I’ve recently published a new blog article on the Grafana Labs blog that guides the reader through the process of creating a re-usable use case specific dashboards based on logs using Grafana Loki as the data source.
Hi all, I haven’t written anything for a long time due to various reasons. I’m now a happy Solutions Engineer at Grafana Labs working on solutions for our customers in the Monitoring and Observability space and I plan to publish more content regularly soon.
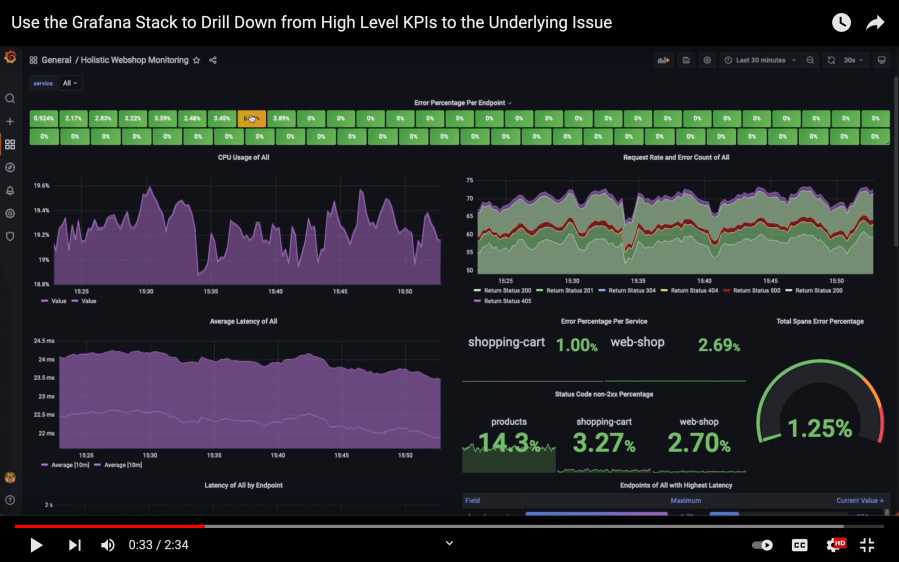
Meanwhile, I have created this short demo video of monitoring endpoints with Grafana using the Grafana stack, i.e., mostly Grafana Loki for managing logs and Grafana Tempo as an OpenTelemetry backend.
In this video you’ll see how to go from high level endpoint metrics, in this case the error rate of the endpoints of a demo web shop application, to a specific trace where an error occurs to the log line that shows what the error message is. Let me know if you have any questions.
Endpoint Monitoring using the Grafana Stack + OpenTelemetry.
In my previous blog I published a video that showed how to query a database table. In the next step I want to show how to enrich this data with data from an external API.
Again: enjoy and don’t forget to ask questions or give me feedback!
Configuration
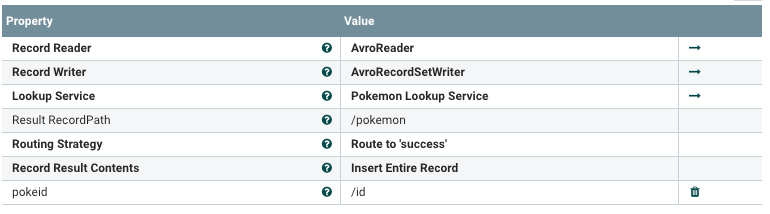
This is how the LookupRecord processor is configured
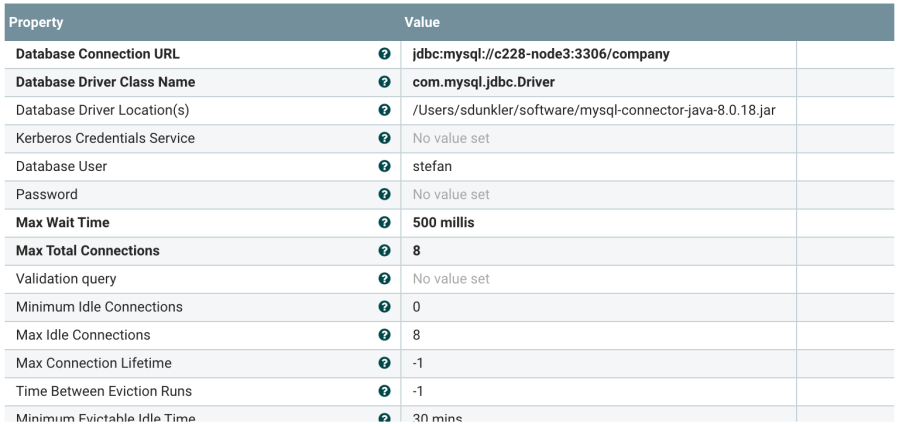
This is how the RESTLookupService (Pokemon Lookup Service) is configured:
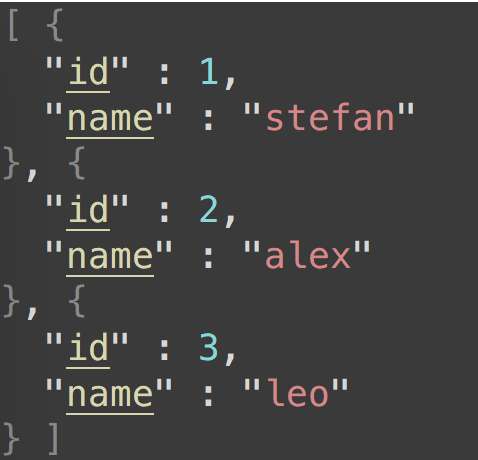
This is the expected input after the QueryDatabaseTableRecord before the LookupRecord processor:
This is an expected output example after the LookupRecord processor:
In order to continue the series “Big Data and Stream Processing 101”, I created a little video to show the most basic operation of Apache Ranger: Apache Ranger can do much more, but the most basic operation is creating a single policy for a single resource and a single user.
It’s not best practice to give single users access to certain resources. For productive setups you’d look more into giving certain roles access to certain resources or tags. But that’s not being discussed here.
While the number of tools in the Open Source Big Data and Streaming Ecosystem still grows, frameworks that are around for a long time become highly mature and feature rich, some may say “enterprise ready”. Thus, it’s not surprising to me to see a lot of my customers who are new to the whole ecosystem are struggling understanding the basics of each of these tools. The first question always is, “When do I use which tool?”, but this is often not enough without having seen a certain tool in action.
This and a tweet that I recently stumbled upon, were motivation enough for me to explain the most basic things you can do with these tools. Each future blog post will contain a description of the most basic operation of exactly one tool and a detailed explanation of this and only this basic operation and none of the advance features, that might confuse beginners.
One motivation for me to write this blog post.
In this first blog post of the series, I want to categorise the tools – as good as possible – and describe each of them with as few words as possible, ideally less than a full sentence. Then I’ll introduce each of these tools in arbitrary order in subsequent blog posts. This should help anybody get started and then attend trainings or do self study to get to know all the features that are supposed to make our lives easier processing and managing data, and lower the barrier to get started with each of these.
Disclaimer: this overview is highly opinionated, most probably biased by my own experience and definitely incomplete ( = not exhaustive). I’m definitely up for discussion and open for questions on why I put a certain tool into a certain category and why certain categories are named as they are. So don’t hesitate to reach out to me 🙂
Tools and Frameworks
I’m re-using the slides that I recently created for a “lunch and learn” session. You’ll notice that a lot if not all of the tools appear in multiple categories.
( ) parentheses mean that I had some issues and spent some time considering if I really would put this tool in a certain category, because it strictly doesn’t fit. I probably put it there, because it *can* be used or it is often *used in combination* with tools in this category.
[ ] parentheses mean that the tool is not very popular anymore. It might still be supported, highly used and mature, but is just not popular anymore and likely to fade away and being replace by another tool.
All – Categorized by Function
“All” doesn’t mean every past and future existing tool in the ecosystem. All in this article means just all the tools that I consider and that are available in one of the distributions of HDP, CDH or the new Cloudera Data Platform (CDP)
Note: “Technical Frameworks” are not frameworks you’d work with on a daily base or at all. They’re just there and enable the rest of the cluster to work properly or enable certain features. All of the frameworks/tools/projects in this category are very different from each other.
Processing – Categorised by Speed of Data
Here “Data at Rest” means, that data could possibly be old, historic data, while “Streaming Data” considers event based/stream processing – processing of data while it’s on it’s why from creation at the source to the final destination. The final destination could be a “Data at Rest” persistence engine/database.
Databases – Categorised by Latency
Latency here could refer to two different things:
How up-to-date the data in the database is
How long a query to the database takes to respond with the results
I don’t distinguish those two in this categorisation, which would make this exercise a bit too detailed and tedious. Generally, it’s important to consider both to choose an adequate database for a certain use case.
All – Categorised by Use Case
I chose four typical use cases for this categorisation. A lot of other use cases can be realized
List of All Tools and Frameworks
Again, “All” doesn’t mean all tools currently available in the open source big data ecosystem. “All” means the bulletproof, tested, compatible set of components that easily cover the most common Big Data and Streaming use cases.
Apache NiFi: Manage data flows; get data from A to B and process it on the way with a UI
Apache Spark: Use dataframes to extract, transform and load data, train and evaluate ML models.
Apache Kafka: Publish, persist and subscribe to events
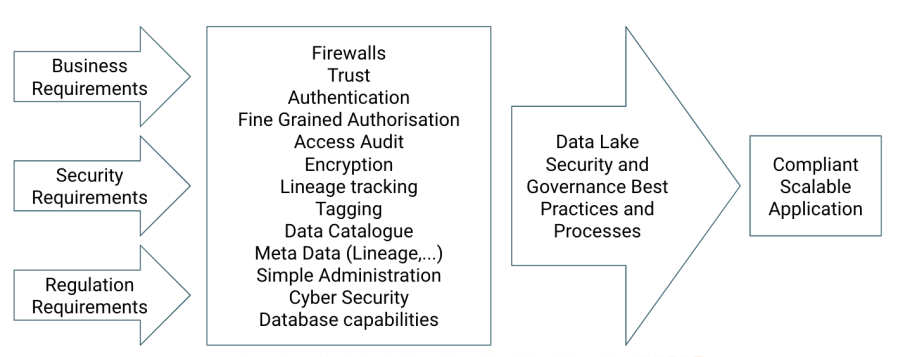
The initial idea of so-called data lakes was to be able to process, transform and dig through huge data sets of unstructured, semi-structured and structured data. It was fairly simple. You put your data set on a Hadoop Distributed File System cluster, you wrote one or multiple MapReduce jobs, which parallelised the processing steps to retrieve the results you were aiming for. Nowadays, it’s not that simple any more, since the number of data bases, tools and frameworks, which are supposed to make this work easier, but also more secure, grew rapidly. This article is a side product of a talk I gave for a Cloudera Foundation project and depicts the history of Data Security and Data Governance. I start in Wild West like scenarios, in which data lake security was neither an option nor a requirement and nobody actually talked about data governance yet. In the course of this article we walk through different epochs to the present describing state-of-the-art capabilities of data lakes for companies to make as sure as possible that neither their data lakes are being breached, nor Personally Identifiable Information (PII) is leaked. The epochs I’m describing are just like the real Stone Age, Bronze Age, Iron Age,… – very dependent on the location, some regions are further developed, some regions are slower but may skip eras. Hence, the estimated time windows are only vaguely defined.
Data Lake Stone Age (5-15 Years Ago)
In the beginning, a lot of companies had one or a few huge data sets for mostly one or a few single use cases. The only way of securing this data was a firewall to block users from having access to the cluster. If you had network access to the cluster, you had access to the data on the cluster. Or in other words: there was nothing else that prevented users from accessing the data anonymously, but the firewall. For some companies or departments, especially smaller ones, this was acceptable, it was fairly easy to implement and it was based on mutual trust between the stakeholders, the data owners and users of the data platform.
Trust as a Security Measurement is Simply Not Enough
This approach was a good – and the only – way to kick off the project “data lake”. As the number of data sets grew on the data lake, the number of stakeholders grew and suddenly – oh surprise – the concept of mutual trust as a security measurement began to fail. Not only was it impossible that all users would know each other so well, as to trust each other, two more risks are always introduced, when multiple people work together: human failure, and conflict of interests. It soon became a requirement to build “secure” data lakes.
I remember being at a data conference and I listened to a talk about data infrastructure. They explained all the fancy stuff they were doing, emphasised multi-tenancy and high flexibility and scalability and a few other buzzwords. At the end of the talk there was a question from the audience: “How do you do all of this with ‘Security enabled’?“. The answer: “Well, we don’t have ‘Security enabled’ on our data platform.” That was 2016.
Bronze Age: What does “Secure” Actually Mean? (4-10 Years Ago)
The basic idea of securing a cluster is to grant access of certain persons to certain data sets and restrict access to others. Almost every database technology comes with one or more ways to define policies that enable the administrator to define who can access which data set within this database. This is known as authorisation. The issue here is that you still need a mechanism to prove to the database system who you are. This is known as authentication. Usually this involves a username and a password to match. This sounds simple, but working on scalable, distributed systems this causes complex challenges that have been solved in different ways, one of the most wide-spread and at the same time oldest mechanisms leveraged to implement authentication on data lakes is the Kerberos protocol.
Becoming Compliant was Possible – Not Easy
At that time, we could authenticate ourselves and access data that we were authorised to use. So, what else did we actually need? Especially in – but not limited to – the financial services industry, it was always a requirement to keep an access log, answering the questions of who was reading data or writing data and when that happened. Most database systems can deliver on that. In the meantime, the world of (open source) databases and data storage engines got quite complex and manifold. There’s a data storage system for each use case you could possibly think of: Do you need to archive raw data at a cheap rate and keep it available for processing later? Do you want to do simple, yet low-latency lookups of certain key words and retrieve information associated with these? Do you want to be able to full-text search documents? Do you want to do SQL queries that are not time critical or rather implement real time dashboards? All of those use cases require your data to be stored in different database systems, sometimes the same data is stored multiple times differently in multiple different database systems following the so-called polyglot persistence architecture. All of those different systems have a way of authentication, authorisation and audit and all of them work similarly, but are more or less different. And exactly this makes it insanely complicated to administrate: they are many different systems with their own implementation of “Security”.
One Service to Secure them All – Problem Solved!?
Retrospectively, the next possible development was as necessary, as it is now obvious. We needed services that could administrate authorisation and collect audit logs in a single point. The development of tools, such as Apache Ranger and Apache Sentry was initiated. It was suddenly easier and more scalable to manage role based security access policies across multiple database systems, also referred to as role based access control (RBAC).
Iron Age: Why Data Lakes are not Necessarily Like Wines (1-6 Years Ago)
While security was one problem that seemed to be fixed, companies wanted to answer more questions about their data – especially because the risk of losing data or data in a data lake becoming worthless was imminent, if they didn’t. These questions were:
Where does my data come from? (Lineage)
What are the processing steps of the data I’m using?
Who owns the data I’m using?
Who is using the data I own?
What is the meaning of the data sets available in a data lake?
If you couldn’t answer these questions, while you were still on-boarding new data sources on a daily base and continuously granted data access to new people, you soon had a problem. You had a data swamp. [Play ominous music in the background while reading the last sentence].
A data swamp is a deteriorated and unmanaged data lake that is either inaccessible to its intended users or is providing little value.
Data Lakes are less like wines, that become better with age, but more like relationships, that become better if you take care of them. [At least that’s what people who have friends tell me].
The Toolset is Expanded and New Roles Emerge
Similar to the Iron Age which is marked as the time when humans started to create superior tools made out of iron, the Iron Age for data lakes starts in your company, when you can answer the questions above efficiently, correctly and in a scalable way. Much as in the Iron Age, this requires appropriate tooling that hasn’t been there before. One of those tools emerging in the Open Source world was Apache Atlas. It started rudimentarily, but grew rapidly with the companies’ requirements. In the beginning you could tag data stored in a few data storage systems and display their linage. Later, the number of supported systems grew due to open standards and the meta data categories you could assign were expanded. A demand for a new role emerged, the data steward, a person, who is responsible to make sure meta data questions around a data lake can be answered at all times. Unfortunately, the name of the role sounds as boring as the role is important.
Next Level: Producing Steel in the Iron Age
After reading through a few of the previous paragraphs, I think you get the hang of it: The number of data sets grows again, the number of users grows again and as a result new problems emerge: we reached a point now, where it is simply painful to manage security policies and at the same time keep track of them. At this point there might be hundreds of policies per database, each policy matching a certain role/group with a certain data resource. This new challenge required new capabilities of a modern data platform and similar to the Habsburg success strategy “Tu felix Austria nube”, security and tagging capabilities were married. Henceforth, it was possible to create tag based policies, and thereby reducing the number of security policies by orders of magnitude.
One More Problem to Solve
An issue that hasn’t been discussed specifically in this article yet, but should be mentioned: encryption. There’s two types of encryption:
“Wire Encryption”: SSL/TLS encryption we face every day in our browser windows, when we visit a website with the prefix https – as opposed to http – “s for secure”. This is called wire encryption, encrypting the communication between two servers and I’m not going to explain here why this is important. This was done multiple time on the internet, e.g., here.
“Encryption at rest” describes data persisted in any storage system, e.g. a local hard drive, a distributed file system or any database system. Especially in times where you might not take care of your own infrastructure (data center, cloud vendor,….), encryption at rest makes sure, that those who administrate the infrastructure and possibly assign policies cannot actually use the data. The encryption key stays with the designated user or is managed on separate Key Management Servers (KMS) to guarantee that only those who are allowed to use the data (beyond policy assignment) can see the data.
Medieval Times: How to Deal with Regulations and External Policies (0-3 Years Ago)
One might ask themselves, why I would compare the time of regulations and governmental policies with the medieval times, often known as the dark ages. One good analogy is that, we have most of the required tools available from earlier times, but we are just not using them. And this is were the analogy ends already: the reasons of not leveraging technology in the medieval times were very different ones…
Let’s recapitulate what we have so far:
Growing number of data sets
Growing number of users
Polyglot persistence
A set of tools to address security challenges
A set of tools to address governance challenges
On top of this, new regulations such as the General Data Protection Regulation (GDPR) pose new challenges. An overly brief and overly simplified summary of what GDPR means for a data lake can be found below:
We need the consent to the processing of people’s personal data.
We need to fulfill contractual obligations with a data subject, i.e.,
provide information to the data subject in a concise, transparent, intelligible and easily accessible form,
delete any data subject related data on request.
We need to protect the vital interests of a data subject or another individual through
pseudonymisation or tokenisation,
keeping records of processing activities,
and securing of personal data.
A solution to this is, on the one hand following best practices as well as establishing processes on the data lake using the existing tools. On the other hand, the solution is very individual. Similar to designing a data application based on certain business requirements, we need to make security and privacy considerations specific for this use case part of these requirements. Example: if a certain data set contains PII that could possibly be presented to the outside, we have multiple options. For example, we could use a storage engine that supports tokenisation of certain fields of PII. If the storage we need to use to deliver our use case requirements does not support tokenisation, then we would need to make sure to tokenise, anonymise or encrypt those fields at the time of data ingestion. If,… – I hope you get the idea. It’s important to look closely into your requirements and then carefully architect a solution based on the capabilities of the data platform and the processes you put in place.
Best Practices to Become and Stay Compliant
Above mentioned best practices and processes can be summarised as:
Establish processes to manage
consent,
transparency and intended usage,
automatic processing of personal data.
Leverage dynamic masking and access control: use roles, tags, location and time to restrict access.
Use the tools and its capabilities mentioned in this article efficiently.
Become a user and customer-centric organisation: Design your applications with your customers as your most important asset. This makes it easier for you to manage and delete customer related data (and to make your customers happy as a side effect).
Renaissance: No System is 100% Secure (0-2 Years Ago)
This article focused on how to prevent data breaches and make it as difficult as possible for people with malicious intent to get access to data they shouldn’t have. However, what can go wrong will go wrong and even if we try our best, we are still human beings. We all do mistakes and since (personal) data is highly valuable, which is the main reason we take so many different measurements in the first place, there will always be people who want to get this data to use and abuse it. There’s no system yet to protect us from social engineering and data breaches happen on a regular base. In addition to that, the “Internet of Things” (IoT) adds a higher attack surface (= number of possibilities to enter a system without permission) than ever before.
Therefore, it’s mandatory to work closely with our cyber security colleagues to be able to detect breaches and respond to them as soon as possible as well as to have a good backup and disaster recovery plan. Modern data lakes are commonly built using the very same technology that powers their business use cases to also power their cyber security and threat hunting efforts.
I’ve worked quite a bit with Apache Metron, a cyber security platform running on a data lake. and written quite a bit about it on this blog.
The Future: New Regulations and Governmental Policies and Technology
The number of governmental regulations will grow in the future and they will be very specific to specific countries. Some kind of data is not allowed to leave certain countries. Some kind of data will always be inspected by certain governments, when it leaves the country. New and additional data privacy and governance regulations will be published as the existing ones are being tested in the wild. More requirements always means more complexity. This shouldn’t worry you, since you know your data platform and it’s databases, it’s security capabilities, as well as it’s data governance capabilities. Furthermore, you have well educated data architects and engineers who not only know how to translate business requirements into a data architecture, but also security requirements and governance requirements of internal and external regulations and policies into the same data architecture.
Framework to overcome security and data governance challenges.
I’m also pretty sure, that there will be regulations that will bring challenges that will be difficult to overcome – if not impossible at that time. The beautiful thing is that all companies (that are affected by this regulation) will face this challenge and they might find their specific ways to overcome those challenges, or – and that’s what happened multiple times in the past – companies work together on open source software to overcome those challenges together.
I Barely Used the Word “Cloud” in this Article! What’s Wrong with me?
Cloud is just one (major) option to store and process the data and provides challenges as well as opportunities. Your cloud provider of choice might not have a data center in the country you produce the data (= challenge). You might not have a data center in the country you produce the data, but the cloud provider has (= opportunity). Basically, treat cloud as part of your tool set to solve challenges and use it as you would use every tool, knowing that it has advantages and drawbacks.
Outlook
This article described roughly the history of security and data governance of data lakes (as far as you can put those items on a strict timeline). Each of those historic additions to the data lake security and governance ecosystem are essential building blocks and tools and all of them are still as relevant as at the time of their introduction. It’s up to you to put them to use and leverage all of their capabilities to make your life easier and your data more secure, manageable and compliant.
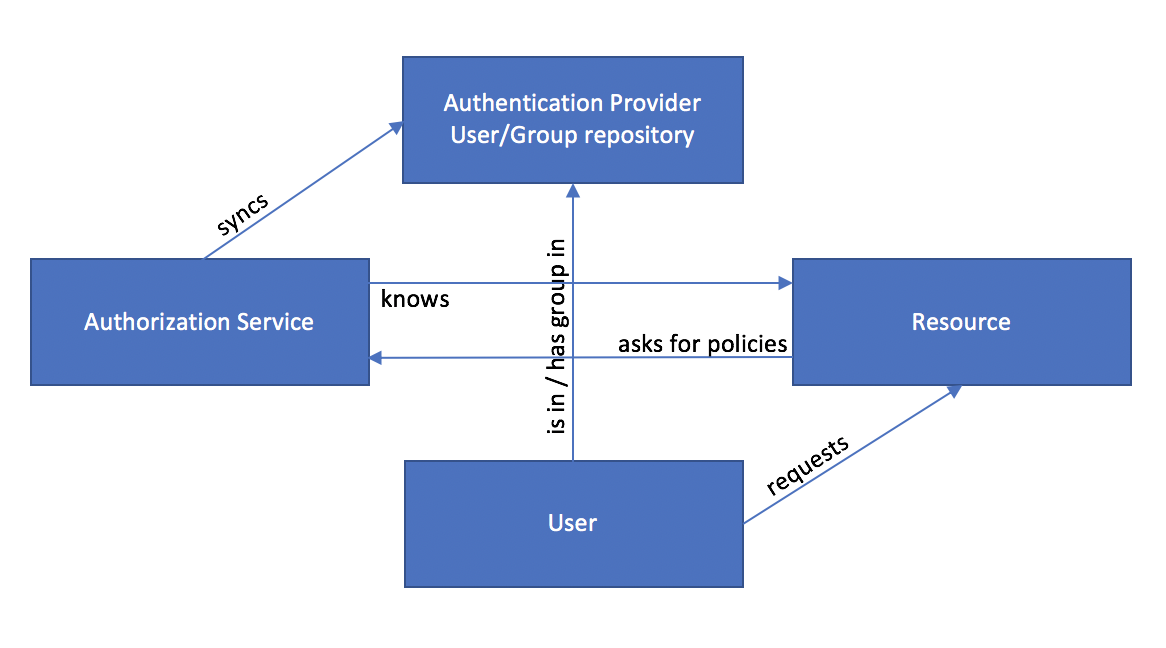
The answer to this question is resource based authorisation. Everybody is familiar with resource based authorization. It’s about managing a set of policies for all resources, i.e., databases, tables, views, columns, processes, applications and others. That means whenever you create a new resource, you need to create a new policy that matches this resources with users or groups and assigns adequate permissions to them.
In resource-based authorization security policies match resources with users/groups.
Thus, authorization services must be aware of the resources (from a specific resource providing service) as well as users and groups (usually from an authentication provider, such as an Active Directory).
The Process
The authorization service connects to the resource-providing service to be aware of the resources. The service typically knows which types of permission the specific resources allow for. In the diagram below you see a simplified process of how resource based authorization typically works and how the “stakeholders” interact.
Typical components and interactions involved in resource based authorization
In the Big Data landscape the de-facto standard authorization service is Apache Ranger.
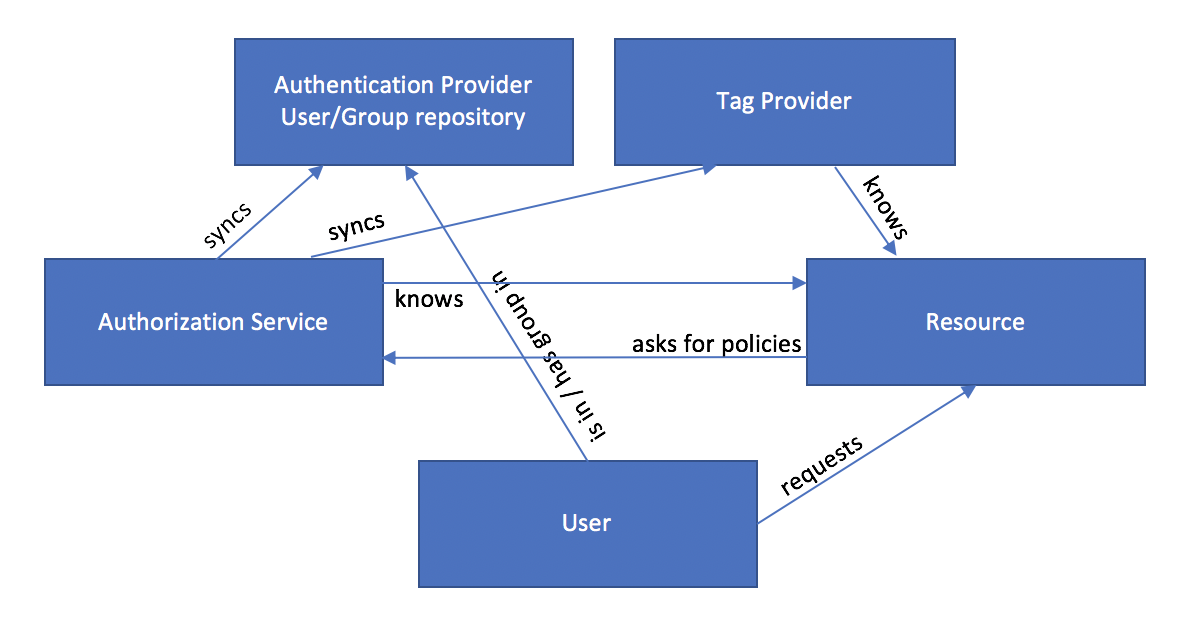
Tag Based Authorization
Tag-based authorization is not so much more different. Instead of having a set of policies that match resources with users/groups, you create a set of policies that match tags with users/groups. This means also, that you need another instance or service to match resources with tags. Now, whenever you create a new resource, the only thing you need to do is to tag it. All existing policies for that tag will automatically apply for the new resource. This gives you more flexibility if you have a complex authorization model in your company, because one tag might be connected with multiple security policies:
It saves you from duplicating the same policies from similar resources
It’s more user-friendly and comes more natural to assign tags to a resource than thinking about which permissions/policies might be required, everytime you add a new resource.
In tag-based authorization security policies match tags with users/groups.
The Process
As mentioned before, an additional service is needed to manage the relationship between resources and tags. The authorization service knows the resource, syncs user and groups as well as the tags for the resources. The tag provider knows the resource and is the interface for the user to assign tags to the resource.
Typical components and interactions involved in tag-based authorization.
You can manage tags and govern your data sources using Apache Atlas. Apache Atlas integrates well with Apache Ranger and other services in the Big Data Landscape and can be integrated with any tool by leveraging its REST API.
Create Useful Tags
Tagging is powerful, since you can look from different angles at your resources, i.e., you can introduce multiple dimensions. Once you decided to go with tag-based security, the first step is to think about which dimensions you want to introduce in the beginning. The second step is to consistently apply those dimensions across your resources.
You can think of dimensions as categories of tags:
One category of tags classifies a resource, e.g., a database based on the source system the data came from: MySQL, Server Log, HBase, …
Another category of tags introduces the dimension of use cases: cyber_security, customer_journey, marketing_campaign2, …
A third category might be the career level within a company: common, manager, executive
Another category of tags distinguishes departments: sales, engineering, marketing, …
As long as you are consequently tagging your resources appropriately, the advantages of tagging in the context of authorization are immediately apparent: When you create a new resource, for example a Hive table, you apply the tags MySQL, customer_journey, executive, marketing and based on the pre-defined tag-based policies you’ll know that
The technical user, that does the hourly load from the MySQL database to Hive has write access to the table.
The team of all people that work on the customer journey project has read access to the table.
All employees on the executive level have read access to the table.
The marketing department has full access to the table.
Conclusions
I hope this article made it easy to understand the process and benefits of tag-based authorization. However, simplified security is only one of the benefits of tagging. Tagging is also useful to describe lineage and thus facilitate data governance.
Apache Metron processes telemetry event by event in real time. Each type of event comes with its specific set of fields. E.g., a proxy log will always contain a source and a destination IP address. A log-on event will always contain a username of the person who wanted to log on. Adding fields to this set of fields in the processing pipeline from other data sources is called an enrichment. Metron offers multiple ways to enrich your telemetry.
This blog entry focusses on enrichments performed with Metron’s scripting language Stellar and shows the usage of 4 useful functions.
Types of Enrichments
First, let’s have a look at the Metron Enrichments documentation. You’ll find that there are multiple types of enrichments: geo, host, hbaseEnrichmentand stellar. As mentioned, we’ll discuss only stellar enrichments here, which is a powerful scripting language to get data from various sources and transform it to make it suitable for our use cases.
Before we start: as with every modern data app, always keep the use case in mind. Enrich and transform your data because it really makes your life easier and your job more fun (and provides some business value ;-)). If you do it because it’s just nice to have or just because it’s possible, you are wasting time to implement it, as well as computing power.
ENRICHMENT_GET: Similarly to the hbaseEnrichment, which does a simple HBase look-up of the column family “t” on the “enrichments” table, you can do HBase look-ups. However, with ENRICHMENT_GET you can specify which table and column family to use for the lookup.
An ENRICHMENT_GET call made up of 4 string arguments looks like: ENRICHMENT_GET('userinfo', 'myuserid', 'mytable', 'mycf'). This performs a “get” query to the HBase table mytable using the composite key of userinfo and myuserid to retrieve all values stored in the columns of the column familiy mycf. All function arguments can be replaced by variables. This implies that you could use a different table, column family and key for each event even within a single data source based on derived values of each event. However, in reality, the most common (and maintainable and predictable) scenario is, to only use the second parameter as a variable and keep the other arguments constant for a certain parser and scenario.
Let’s have a look at a detailed example: Assume, we have onboarded a static enrichment source in HBase called userinfo using the HBase table static_enrichments and the column family s. For each user with a certain ID we have stored the following data:
This map will be indexed to Elastic Search or Solr as
userinfo:firstname --> Sara userinfo:lastname --> Great userinfo:employee_status --> retired
If you wanted to manipulate those values directly in a Metron workflow, e.g., to evaluate the employee status, you need to extract the value using the MAP_GET function.
This assigns the value of the employee_status field of the userinfo map to the variable userinfo:employee_status. You can now use the employee status of the current user for further evaluations, e.g. to check if they are active.
This will create a flag is_active_user as a new field that will be indexed. You can use this flag to define alerts and do scoring in Metron. In Elastic/Solr you can filter for active users using this boolean flag.
For comparisons TO_LOWER and TO_UPPER are essential. Before doing an enrichment converting one of our example usernames from AXC12345 to axc12345 will ensure that the lookup to HBase is successful
Sometimes you don’t want to add a ton of new fields to be indexed or you don’t even need all of the fields. You rather want to check if there *is* an enrichment at all. This can be used for blacklisting or whitelisting. Imagine you have an enrichment that looks somewhat like this, a HBase table whitelist, a column family b and an enrichment type domains.
key
whitelist:b
domains example.com
{“domain”: “example.com”}
domains anotherexample.com
{“domain”: “anotherexample.com”}
You see, that this table does not even contain useful additional information. You only want to check if a certain domain is blacklisted/whitelisted, like so:
Above example will yield true for is_blacklisted an can later be used in threat intel logic and score assignment. It is also indexed to Solr/Elastic Search automatically.
Conclusion
Using Apache Metron, you can do powerful real-time enrichments for all kinds of use cases. Stellar is a powerful tool within Metron to help you do complex enrichments, manipulations and transformations in a simple way. There are many more functions. The four functions introduced in this blog entry are very commonly used when you do enrichments.
What is “Cookiecutter”? Cookiecutter is a project that helps create boiler plate and project structures and is very famous and widely used in both the Python and data scientist communities. But you can use Cookiecutter for virtually anything, also for Apache Metron sensors. Apache Metron is,…. well read some of the earlier blog posts, or the documentation. 🙂
What is the cookiecutter-metron-sensor Project?
The cookiecutter-metron-sensor project helps you to create sensor configuration files and it generates deployment instructions and a corresponding deployment script for the specific sensor. If you need all the details check out the README.md of the project on github:
Now simply fill in the prompts to configure the cookiecutter and the lion’s share of the work you need do to onboard a new data source is done. In the directory created you find a deployment script as well as another README.md file that you can use to document everything around your sensor as you go ahead and define your own transformations and enrichments. The README.md comes with the deployment instructions for its own specific parser.
Help to fill in the Cookiecutter prompts
While the cookiecutter-metron-sensor helps you to create and complete all of the Metron sensor configuration files, it does not do anything to explain what those prompts mean. You still need to read the documentation for this. However, to assist you in your efforts I’ll walk you through the configuration prompts and point you to the documentation, so you understand what and why you need to configure it.
sensor_name: This will be the name of the sensor in the Metron Management UI and determines the name of the parser Storm topology and the name of the Kafka consumer group.
index_name: The name Metron will use to store the result of the Metron processing pipeline in HDFS, Elastic Search or Apache Solr.
kafka_topic_name: This is the name of the Kafka topic the sensor parser will subscribe to.
kafka_number_partitions: The number of partitions of the Kafka topic above. It also determines the number of “ackers” and Storm “spouts” of the sensor parser topology. If you’re not sure it’s good to start with 2 and increase this number later on, if you see that the parser topology builds up lag. Check the Metron performance tuning guide for more information.
kafka_number_replicas: The number of replicas of the above Kafka topic. For data security and service availability reasons this should be 2 or 3.
storm_number_of_workers: The number of Storm workers you want to launch for the sensor parser topology. Each worker is it’s own JVM Linux process with memory assigned to it. All Storm processing units will be distributed over these workers. For availability reasons use 2 or more workers.
storm_parser_parallelism: This will affect how fast the sensor parser will be processing the incoming data stream. Per default cookiecutter sets it to your choice of kafka_number_partitions which as mentioned above affect the number of processing units reading the stream from Apache Kafka.
batch_indexing_size: This is the batch size written to HDFS per writer and should be determined based on the parallelism and the number of events per second your are dealing with. Again, refer to the performance tuning guide.
ra_indexing_size: Similar to batch_indexing_size, but for indexing to Elastic Search or Solr.
write_to_hdfs: Select true if you want to use the batch indexing capabilities to HDFS.
write_to_elastic_search: Select true if you want to use the random access indexing capabilities to Elastic Search.
write_to_solr: Select true if you want to use the random access indexing capabilities to Apache Solr.
write_to_hbase: Choose false if you want a “common” Metron pipeline [Parsing/Transforming] –> [Enrichment] –> [Indexing] –> [HDFS/Elastic/Solr]. Choose true if you want to onboard a stream ingest enrichment source [Parsing/Transforming] –> [HBase]. shew_table: The HBase table name you want to write to in case you use write_to_hbase. You can ignore this and use the defaults in case you don’t. shew_cf: The HBase column family name you want to write to in case you write_to_hbase. You can ignore this and use the defaults in case you don’t. shew_key_columns: The name of the field you want to act as the lookup-key for you enrichment source in case you write_to_hbase. You can ignore this and use the defaults in case you don’t. shew_enrichment_type: The name of the enrichment to uniquely identify this, when you want to use this enrichment. It will be part of the lookup-key. Only important in case you write_to_hbase. You can ignore this and use the defaults in case you don’t.
parser_class_name: Select one of the possible parsers. Note: As all of these values, you can change that later in the Metron Management UI if you are using a custom parser or can’t find you parser in this list.
grok_pattern_label: Per default this is the sensor_name in upper case letters, but you might want to change this.
zookeeper_quorum: This is important for the deployment script so you can create a Kafka topic. If you deployed Metron using Ambari you’ll find this information in the Ambari UI.
elastic_user: Important for the deployment. If your Elastic Server does not use the X-Pack for security you can leave this field empty.
elastic_master: The URL to the Elastic Search Master server
metron_user: An admin user that has access to the Metron REST server
metron_rest: The URL to the Metron REST server.
Note: This cookiecutter-metron-sensor project is very young and work in progress to continuously add new features with time with the aim to make it even easier for a cyber security operator to master threat intelligence data flows.