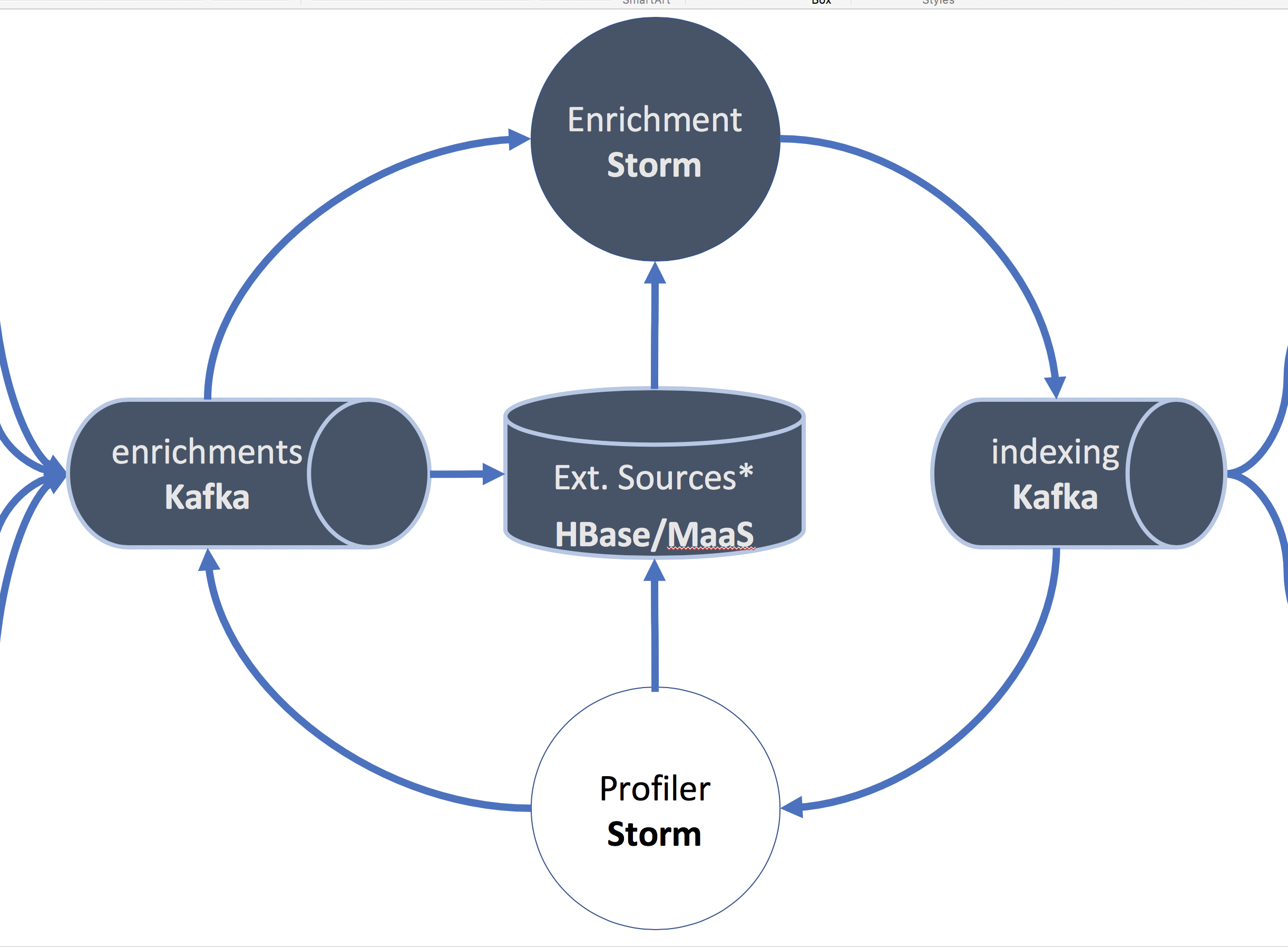
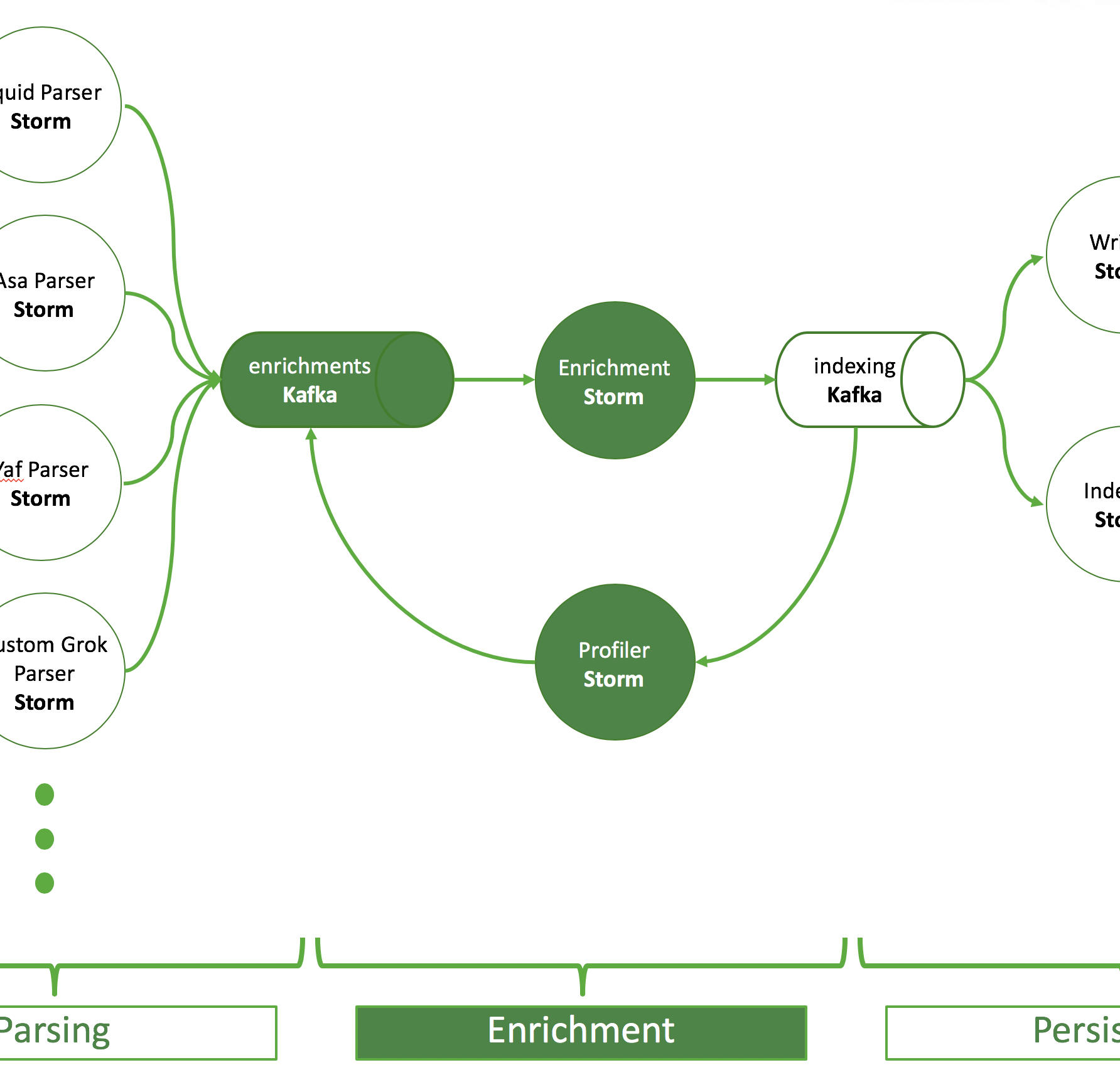
Apache Metron processes telemetry event by event in real time. Each type of event comes with its specific set of fields. E.g., a proxy log will always contain a source and a destination IP address. A log-on event will always contain a username of the person who wanted to log on. Adding fields to this set of fields in the processing pipeline from other data sources is called an enrichment. Metron offers multiple ways to enrich your telemetry.
This blog entry focusses on enrichments performed with Metron’s scripting language Stellar and shows the usage of 4 useful functions.
Types of Enrichments
First, let’s have a look at the Metron Enrichments documentation. You’ll find that there are multiple types of enrichments: geo, host, hbaseEnrichmentand stellar. As mentioned, we’ll discuss only stellar enrichments here, which is a powerful scripting language to get data from various sources and transform it to make it suitable for our use cases.
Before we start: as with every modern data app, always keep the use case in mind. Enrich and transform your data because it really makes your life easier and your job more fun (and provides some business value ;-)). If you do it because it’s just nice to have or just because it’s possible, you are wasting time to implement it, as well as computing power.
The Functions
ENRICHMENT_GET
ENRICHMENT_GET: Similarly to the hbaseEnrichment, which does a simple HBase look-up of the column family “t” on the “enrichments” table, you can do HBase look-ups. However, with ENRICHMENT_GET you can specify which table and column family to use for the lookup.
An ENRICHMENT_GET call made up of 4 string arguments looks like: ENRICHMENT_GET('userinfo', 'myuserid', 'mytable', 'mycf'). This performs a “get” query to the HBase table mytable using the composite key of userinfomyuserid to retrieve all values stored in the columns of the column familiy mycf. All function arguments can be replaced by variables. This implies that you could use a different table, column family and key for each event even within a single data source based on derived values of each event. However, in reality, the most common (and maintainable and predictable) scenario is, to only use the second parameter as a variable and keep the other arguments constant for a certain parser and scenario.
Let’s have a look at a detailed example: Assume, we have onboarded a static enrichment source in HBase called userinfo using the HBase table static_enrichments and the column family s. For each user with a certain ID we have stored the following data:
| row key | static_enrichments:s |
| userinfo axc12345 | {"userid": "axc12345", "firstname": "Max", "lastname": "Power", "employee_status": "active"} |
| userinfo brt98764 | {"userid": "brt98764", "firstname": "Sara", "lastname": "Great", "employee_status": "retired"} |
The Stellar expression below
userid := 'brt98764'
userinfo := ENRICHMENT_GET('userinfo', userid, 'static_enrichments', 's')
extracts a map with the following values
userinfo:
{
"firstname": "Sara"
"lastname": "Great"
"employee_status": "retired"
}
This map will be indexed to Elastic Search or Solr as
userinfo:firstname --> Sara
userinfo:lastname --> Great
userinfo:employee_status --> retired
If you wanted to manipulate those values directly in a Metron workflow, e.g., to evaluate the employee status, you need to extract the value using the MAP_GET function.
MAP_GET
This function should be used to extract the value of a field from a map, e.g., from a map obtained from a HBase enrichment. In Stellar you could do
userinfo:employee_status := MAP_GET(userinfo, 'employee_status')
This assigns the value of the employee_status field of the userinfo map to the variable userinfo:employee_status. You can now use the employee status of the current user for further evaluations, e.g. to check if they are active.
is_active_user := userinfo:employee_status == 'active'
This will create a flag is_active_user as a new field that will be indexed. You can use this flag to define alerts and do scoring in Metron. In Elastic/Solr you can filter for active users using this boolean flag.
TO_LOWER/TO_UPPER
For comparisons TO_LOWER and TO_UPPER are essential. Before doing an enrichment converting one of our example usernames from AXC12345 to axc12345 will ensure that the lookup to HBase is successful
userid := TO_LOWER(userid)
userinfo := ENRICHMENT_GET('userinfo', userid, 'static_enrichments', 's')
There are many other useful string functions, to split, join or do other operations on strings. Go check them out.
ENRICHMENT_EXISTS
Sometimes you don’t want to add a ton of new fields to be indexed or you don’t even need all of the fields. You rather want to check if there *is* an enrichment at all. This can be used for blacklisting or whitelisting. Imagine you have an enrichment that looks somewhat like this, a HBase table whitelist, a column family b and an enrichment type domains.
| key | whitelist:b |
| domains example.com | {“domain”: “example.com”} |
| domains anotherexample.com | {“domain”: “anotherexample.com”} |
You see, that this table does not even contain useful additional information. You only want to check if a certain domain is blacklisted/whitelisted, like so:
mydomain := 'example.com'
is_blacklisted := ENRICHMENT_EXISTS('domains', mydomain, 'whitelist', 'b')
Above example will yield true for is_blacklisted an can later be used in threat intel logic and score assignment. It is also indexed to Solr/Elastic Search automatically.
Conclusion
Using Apache Metron, you can do powerful real-time enrichments for all kinds of use cases. Stellar is a powerful tool within Metron to help you do complex enrichments, manipulations and transformations in a simple way. There are many more functions. The four functions introduced in this blog entry are very commonly used when you do enrichments.