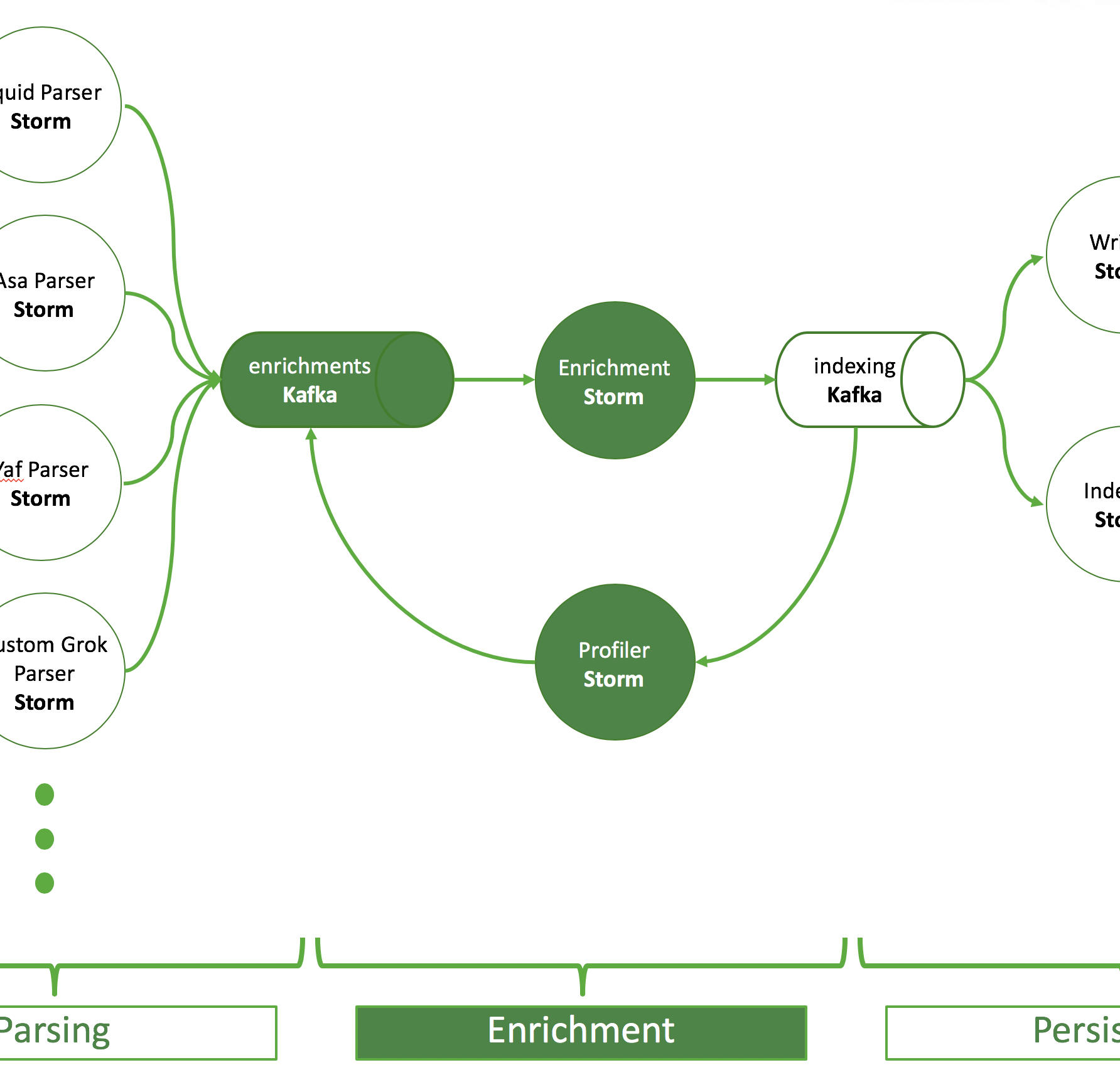
This blog entry goes through the process of a Cyber Platform Operator creating a new parser for Apache Metron and everything you need to consider to make this process as smooth as possible. This can also be seen as a checklist or to-do list when you are creating a new parser.
Assumption: You know what Metron is, the data source is fully onboarded on your platform and the parser config is the only thing that’s missing. Here are the things you need to consider to onboard a new source.
In general, this article walks you through 3 phases:
- Check if you can re-use an existing parser. If so, you’re done, the testing part of phase 2 still applies, though.
- Build and test a protoype. Grok is your friend.
- Write your parser in Java.
Phase 1: Check if you can use an existing parser
- Get a sample set of your source to test with. The more diverse you expect the formats of the same source to be, the bigger your sample size should be. 20 should be ok to start with.
- Check the format of the string.
- If it is in JSON format, use the JSON parser!
- If it’s a comma separated line, use the CSV parser!
- Or generally: If it’s in a format of any of the included Metron parsers, use this parser: CEF, Lancope, PaloAltoFirewall, Sourcefire, Logstash, FireEye, Asa, Snort, JSONMap, Ise, GrokWebSphere, Bro,….
- If it’s something else use the Grok parser!
Phase 2: Build and test a (Grok) prototype
In the rest of the article I assume that you don’t re-use one of the included parsers, which is why you want to create your own custom one. Thus, you leverage the Grok parser. However, the test setup described below and can be used for any kind of parser.
- Use http://grokdebug.herokuapp.com/ to test one of your samples and start with adding
%{GREEDYDATA:message}and continuously add more precise parsing statements and check if it compiles. If you’re new to Grok start here: https://logz.io/blog/logstash-grok/. - Test all of your samples in the app to check if your Grok statement is general enough.
- You also might want to append
%{GREEDYDATA:suffix}(\n|\r|\r\n)?+to catch any kind of additional data, as well as filter newline and optional carriage-return fields at the end of a line. That depends on how diverse or clean your data source is. - Configure and validate the parser in Metron Management UI using “Grok” as parser type and paste the grok statement in the field “Grok Statement”.
- Attention: don’t forget to define the timestampField, the timeFields and the dateFormat. If you don’t specify those values, the parser validation will fail with an “error_type”: “parser_invalid”. The field configured as the timestampField will be converted into a timestamp parsed based on the inputs from the dateFormat field. Use the Joda time date format documented here.
- When the datetime is correctly parsed, double-check if the calculated timestamp matches the input time. This online epochconverter comes handy.
- Note: to consolidate your view of the data across many sources, make sure you name the source ip address “ip_src_addr”, your destination ip address “ip_dst_addr”, your source port “ip_src_port” and your destination port “ip_dst_port”.
- Note: In general, every parser – not only the Grok parser – has their specific required/default parameters to be set. Read the parser docs to be sure to configure the parsers correctly. Below is an example of how the
parserConfigpart of your parser configuration file should look like. You configure this part in the Metron Management UI:

- Double check:
- If Grok statements are stored in the configured HDFS path:
/apps/metron/patterns/mycustomparser - If the Zookeeper configuration is up to date:
bin/zkCli.sh -server <zookeeper-quorum> get /metron/topology/parsers/mycustomparser. Specifically look for theparserConfigpart shown below.
- If Grok statements are stored in the configured HDFS path:
{
...
"parserClassName": "org.apache.metron.parsers.GrokParser",
"parserConfig": {
"grokPath": "/apps/metron/patterns/mycustomparser",
"patternLabel": "MYCUSTOMPARSER",
"timestampField": "datetime",
"timeFields": ["datetime"],
"dateFormat": "yyyy-MM-dd HH-mm-ss",
"timezone": "UTC"
},
...
}

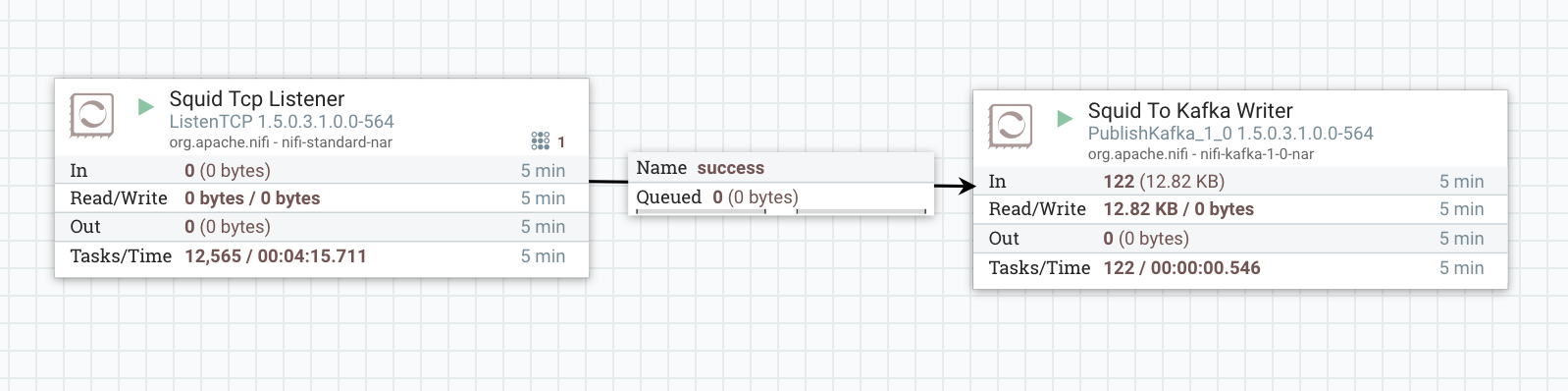
- Ingest the messages into the Kafka topic using your NiFi test setup and check if they are successfully persisted in your desired collection.
Phase 3: Make your Metron parser production ready
Once you have your custom parser up and running and improved it continuously you want to create something more stable with higher performance than Grok statements. However, nothing is for free. You need to get your hands dirty in Java. Fortunately, it’s not a lot of dirt and it’s quite easy to write your own parser by extending the BasicParser class.
- Check out this part of the documentation to get a walkthrough: 3rd party parsers
- In this part of the documentation you’ll learn to:
- Get to know which dependencies you need.
- Implement a parser method of your custom parser class extending the
BasicParserclass. - Build the jar and deploy it in the extra-parser directory.
- Restart Metron Rest service to pick up the new parser from your jar file.
- Add your parser in the Metron Management UI by choosing your parser type.
- Configure and start your parser.
- Stop your interim Grok parser and start your custom Java parser.