In my previous blog I published a video that showed how to query a database table. In the next step I want to show how to enrich this data with data from an external API.
Again: enjoy and don’t forget to ask questions or give me feedback!
Configuration
This is how the LookupRecord processor is configured
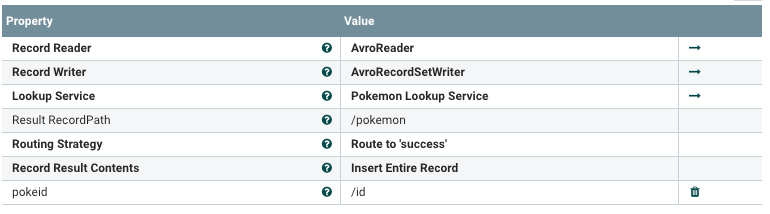
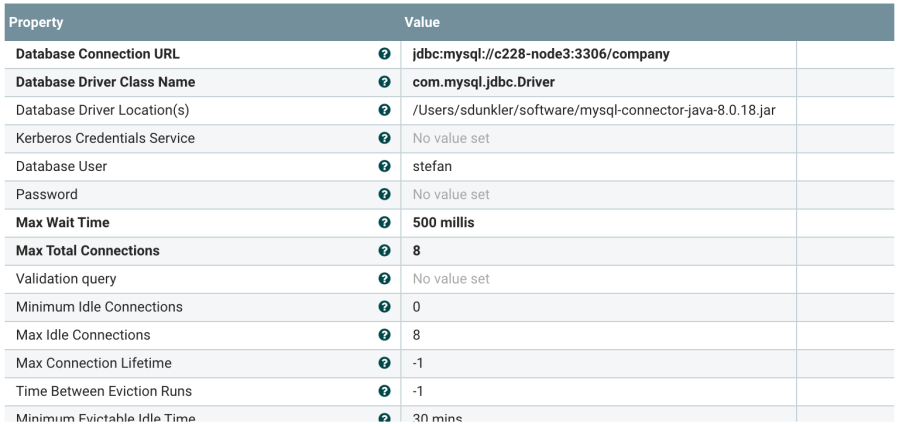
This is how the RESTLookupService (Pokemon Lookup Service) is configured:
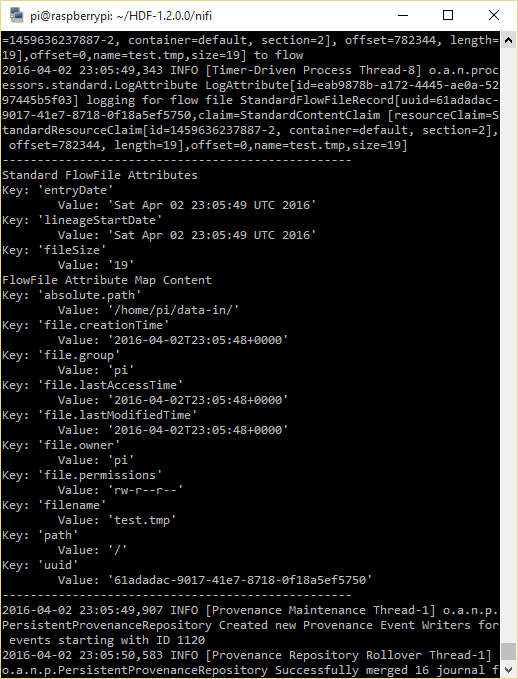
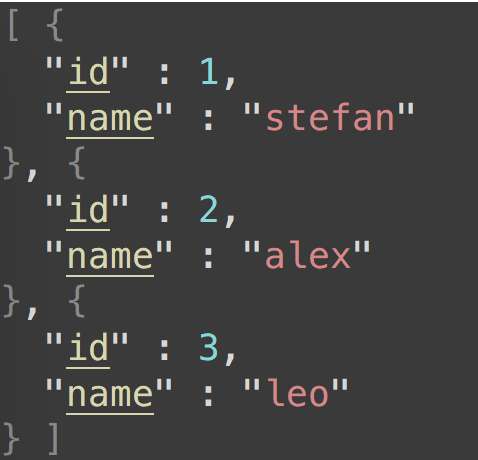
This is the expected input after the QueryDatabaseTableRecord before the LookupRecord processor:
This is an expected output example after the LookupRecord processor:
Apache Metron aims to be a tool for analysts in a cyber security team to help them defining intelligent alerts, detecting threats and work on them in real-time. This is the first blog post in a row to ease operations and share my experiences with Apache Metron. Thus, it serves as an introduction to Metron.
Technical Introduction
Apache Metron is a cyber security platform making heavy use of the Hadoop Ecosystem to create a scalable and available solution. It utilizes Apache Storm and Apache Kafka to parse, enrich, profile, and eventually index data from telemetry sources, such as network traffic, firewall logs, or application logs in real-time. Apache Solr or Elastic Search are used for random access searches, while Apache Hadoop HDFS is used for long term and analytical storage. It comes with its own scripting language “Stellar” to query, transform and enrich data. A security operator/analyst uses the Metron Management UI to configure and manage input sources as well the Metron Alerts UI to search, filter and group events.
Metron Alerts UI, showing a few dummy events from a Squid log.
Scope of this Post
Since virtually every data source can be used to generate events, it is natural that the platform operator/analyst wants to add data from new sources over time. I use this post as a small check list, to document considerations for the “onboarding” process of new data sources. You might want to automate this process in a way that works for you. In future posts I will cover the steps in detail.
Onboard a New Data Source
I need to ingest data to Kafka
It’s very handy to use Apache NiFi for the ingest part. Just create a data flow consisting of two processors: a simple tcplistener to receive data and a Kafka producer to push the event further into Kafka.
I can also push data directly into Kafka if the architecture, firewall and the source system allow it.
If there are no active components on the source system pushing data, I might want to install an instance of MiNiFi on my source system.
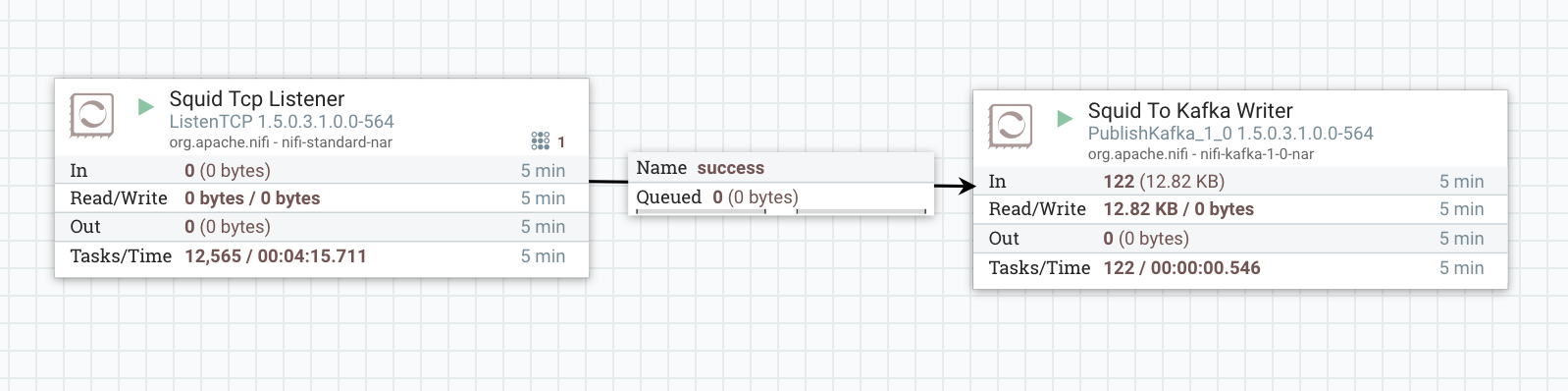
Simple example of a data ingest into Kafka via NiFi
Before I can ingest data into Kafka, I need a new Kafka topic
While the Kafka topics “enrichments” and “indexing” Kafka topics will be used by all data sources, the parser topics are specific to a data source.
I create a topic named “squid” with a number of partitions that corresponds to the amounts of data I receive.
To make the events searchable, i.e., to store the events into Apache Solr, I need to create a new Solr collection (or Elastic Search template)
For each parser Storm topology and parser Kafka topic, there is a parser Solr collection.
I add a few specific fields common to all Metron Solr collections and optionally define data source specific fields in the schema.xml.
I create a new collection named “squid” with a number of shards that corresponds to the amount of data I receive.
I define my parser in the Metron Management UI
I click the “+” button in the right bottom corner of the Metron Management UI.
I configure my parser by choosing a Java class and/or define a Grok pattern, insert a sample and check if the parsed output is what I expect.
I configure the parser: Kafka topic name, Solr collection name, parser config, enrichment defintions, threat intel logic, transformations, parallelism.
I save the parser configuration and press the “Play” button next to the new parser to start it.
Metron Management UI with my configured parsers. Currently only the Squid parser is running that produces the events in the first screenshot.
Outlook
I hope this post was helpful and informative. For questions I refer to the documentation, future posts, the Metron mailing list or post a question below.
The Hadoop Summit is a tech-conference hosted by Hortonworks, being one of the biggest Apache Hadoop distributors, and Yahoo, being the company in which Hadoop was born. Software developers, consultants, business owners, administrators, that have a mutual interest in Hadoop and the technologies of its ecosystem, all gathered in Dublin – this year’s Hadoop Summit of Europe took place in Ireland. The Hadoop Summit 2016 Dublin had some great keynotes, plenty of time to network and a lot of exciting talks about bleeding edge technology, its use cases and success stories. Also it was a great opportunity for companies working with Hadoop to present themselves and for the visitors to get to know them.
Keynote: “Data is Beautiful”
The organisation of the conference was great. 1300 people participated, but it never felt crowded, nor were there any (big) waiting lines to enter the speaker rooms or at the lunch buffet.
My Favorite Talks
This is a list of my favorite talks in a chronological order with their videos embedded. To be honest, this list is basically almost all of the talks that I saw in person and probably I missed even more great talks, that were given in parallel. Fortunately, we can see all of them on the official Hadoop Summit 2016 Dublin Youtube channel.
SQL streaming: This talk gave a really nice overview of the development of an SQL streaming solution with all its technical challenges and how they were addressed. Also simple technical use cases were discussed and compared to traditional SQL, where each query terminates, whereas streaming SQL queries never terminate.
Hadoop at LinkedIn: Here we got valuable insights into the Hadoop landscape of LinkedIn, as well as job monitoring and automated health checks. A job monitoring tool, Dr. Elephant, developed by LinkedIn was open sourced only a few days before the start of the Summit.
Containerization at Spotify: This talk was about how Spotify uses docker containers and the tools involved in their automated IT landscape. The best part starts at 39:30, where it is revealed, that Spotify overcomes security challenges by not implementing internal security measurements at all. According to the speaker everyone can access everyones data. If life could always be as simple as that 🙂
Apache Zeppelin + Apache Livy: Apache Zeppelin already is a great tool for interactive data analysis, exploration or even doing ETL tasks using Apache Pig, querying data using Apache Hive, as well as executing Python, R or bash scripts. Apache Livy helps data scientists work together in one notebook on a secure cluster. What I like a lot about this talk is, that the speakers nicely explain the authentication mechanism involved.
Apache Phoenix: Apache Phoenix is a SQL query engine on top of Apache HBase and much more. This talk was basically a view on the capabilities and features of Apache Phoenix. Great stuff – nothing more to add. Watch the video!
10 Years of Hadoop Party
In the night of day one, the Guinness storehouse was utilized as a huge burger-beer-and-big-data networking event. As you can imagine there was good food, Guinness, great music by Irish bands on several floors and of course most importantly the same cool people attending the conference.
Author in the Guinness storehouse
Summary
My first Hadoop Summit attendance was a great experience in all its particulars. I got great contacts, gained lots of knowledge and had lots of fun at the same time. Hopefully, I will be able to attend the next Hadoop Summit 2017 in Munich.
Apache NiFi is part of the Hortonworks Data Flow (HDF) product and manages data flows. The Raspberry Pi is a small, open source, multi-purpose computer. If you are not familiar with one or more of these products, just follow the links for more information. 🙂
Hardware and Software Specifications
Hardware: Raspberry Pi 2.
Operating System: Raspbian version March-2016 (Download).
should work out of the box, but for me only this works without further modifications:
/etc/init.d/nifi start
After starting, I tried to access the Web Interface, but it didn’t work. I checked the logs, but everything seemed alright. I saw something like the following in the nifi-bootstrap.log
2016-04-02 21:06:29,563 INFO [NiFi Bootstrap Command Listener] org.apache.nifi.bootstrap.RunNiFi Apache NiFi now running and listening for Bootstrap requests on port 47094
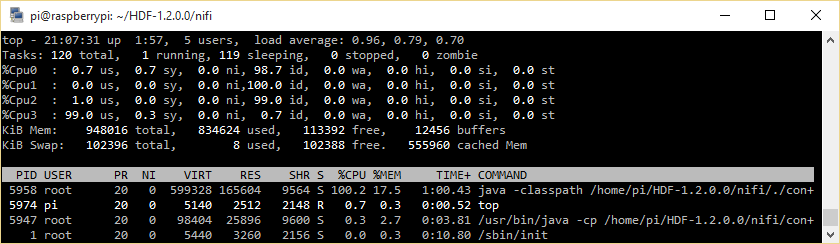
After 6 minutes and 3 seconds, the web interface was available though. As you can see in the screenshot below HDF takes 100% of one core of the RasPi during the start up process:
The HDF start-up process occupies one full core of the RasPi
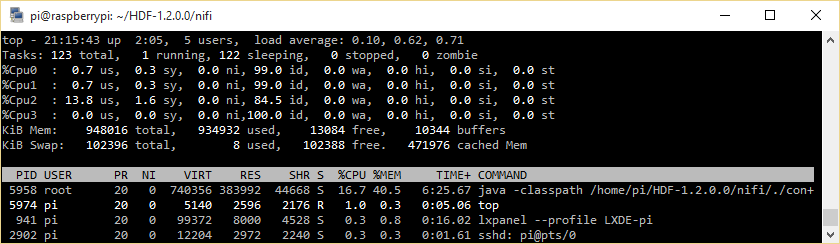
After the webserver is up and running, NiFi’s resource usage looks more moderate:
NiFi needs about 16.7% of (400% of) CPU and almost 40.5 % of the RasPi’s RAM
I followed the “Getting Started” where NiFi is configured to have two processors, one of which reads files from the disk, sends them to the other processor and deletes them. The other processor just receives the files and logs their information to the nifi-app.log. Although the name of the processor “LogAttribute” is quite obvious, the official documentation does not provide a description on what it actually does. I found this amazing blog post on a www.nifi.rocks, where quite a lot of processors are described.
Writing a file, then being deleted by the NiFi GetFile processor 100000 times, then …
…, then getting transfered to the LogAttribute processor, and finally …
… finally the LogAttribute processor logs the incoming FlowFile data in the nifi-app.log.
Conclusion
NiFi is as easy to install on a Raspberry Pi as anywhere else and sticks out with all of its features, being complex but not complicated. I did not test a lot of different processors on the RasPi nor did I test this simple setup with large amounts of data, but even in its simplicity the possibilities are endless. Combining the power and easy of use of the RasPi’s GPIOs with NiFi’s power and simplicity to direct and redirect data (flows), practically every child can, e.g., send temperature sensor data into a Hadoop File System and even process and filter it on its way.









 Containerization at Spotify: This talk was about how
Containerization at Spotify: This talk was about how