The answer to this question is resource based authorisation. Everybody is familiar with resource based authorization. It’s about managing a set of policies for all resources, i.e., databases, tables, views, columns, processes, applications and others. That means whenever you create a new resource, you need to create a new policy that matches this resources with users or groups and assigns adequate permissions to them.
In resource-based authorization security policies match resources with users/groups.
Thus, authorization services must be aware of the resources (from a specific resource providing service) as well as users and groups (usually from an authentication provider, such as an Active Directory).
The Process
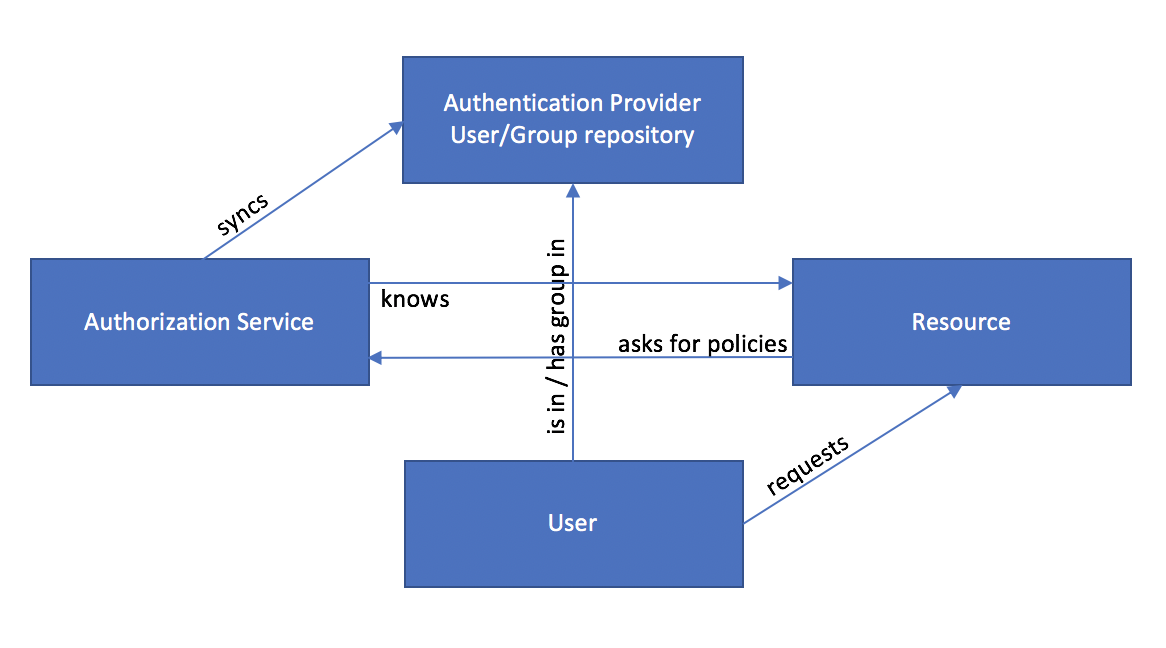
The authorization service connects to the resource-providing service to be aware of the resources. The service typically knows which types of permission the specific resources allow for. In the diagram below you see a simplified process of how resource based authorization typically works and how the “stakeholders” interact.
Typical components and interactions involved in resource based authorization
In the Big Data landscape the de-facto standard authorization service is Apache Ranger.
Tag Based Authorization
Tag-based authorization is not so much more different. Instead of having a set of policies that match resources with users/groups, you create a set of policies that match tags with users/groups. This means also, that you need another instance or service to match resources with tags. Now, whenever you create a new resource, the only thing you need to do is to tag it. All existing policies for that tag will automatically apply for the new resource. This gives you more flexibility if you have a complex authorization model in your company, because one tag might be connected with multiple security policies:
It saves you from duplicating the same policies from similar resources
It’s more user-friendly and comes more natural to assign tags to a resource than thinking about which permissions/policies might be required, everytime you add a new resource.
In tag-based authorization security policies match tags with users/groups.
The Process
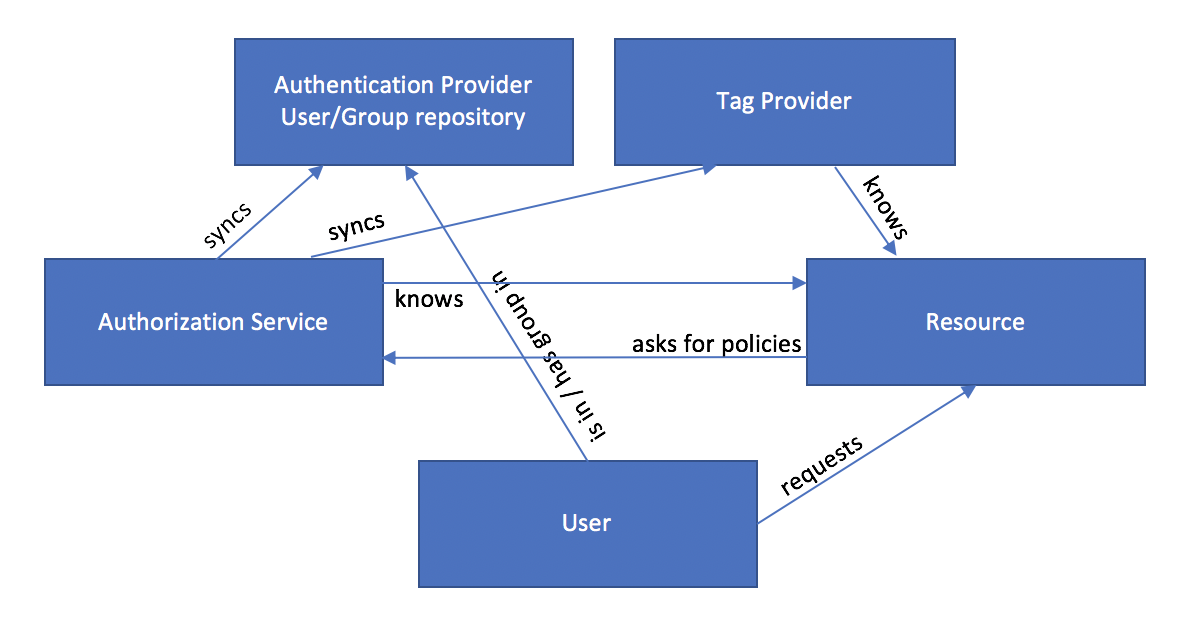
As mentioned before, an additional service is needed to manage the relationship between resources and tags. The authorization service knows the resource, syncs user and groups as well as the tags for the resources. The tag provider knows the resource and is the interface for the user to assign tags to the resource.
Typical components and interactions involved in tag-based authorization.
You can manage tags and govern your data sources using Apache Atlas. Apache Atlas integrates well with Apache Ranger and other services in the Big Data Landscape and can be integrated with any tool by leveraging its REST API.
Create Useful Tags
Tagging is powerful, since you can look from different angles at your resources, i.e., you can introduce multiple dimensions. Once you decided to go with tag-based security, the first step is to think about which dimensions you want to introduce in the beginning. The second step is to consistently apply those dimensions across your resources.
You can think of dimensions as categories of tags:
One category of tags classifies a resource, e.g., a database based on the source system the data came from: MySQL, Server Log, HBase, …
Another category of tags introduces the dimension of use cases: cyber_security, customer_journey, marketing_campaign2, …
A third category might be the career level within a company: common, manager, executive
Another category of tags distinguishes departments: sales, engineering, marketing, …
As long as you are consequently tagging your resources appropriately, the advantages of tagging in the context of authorization are immediately apparent: When you create a new resource, for example a Hive table, you apply the tags MySQL, customer_journey, executive, marketing and based on the pre-defined tag-based policies you’ll know that
The technical user, that does the hourly load from the MySQL database to Hive has write access to the table.
The team of all people that work on the customer journey project has read access to the table.
All employees on the executive level have read access to the table.
The marketing department has full access to the table.
Conclusions
I hope this article made it easy to understand the process and benefits of tag-based authorization. However, simplified security is only one of the benefits of tagging. Tagging is also useful to describe lineage and thus facilitate data governance.
In one of my previous articles I wrote about Apache Metron as an Example for a Real-Time Streaming Pipeline. Since then, I’ve refined the figure I’ve used to explain the architecture. In this article, I just briefly explain the updated part of the figure and add a video of myself talking about Apache Metron at the Openslava conference in Bratislava using those updated figures in my slides.
Enrichment
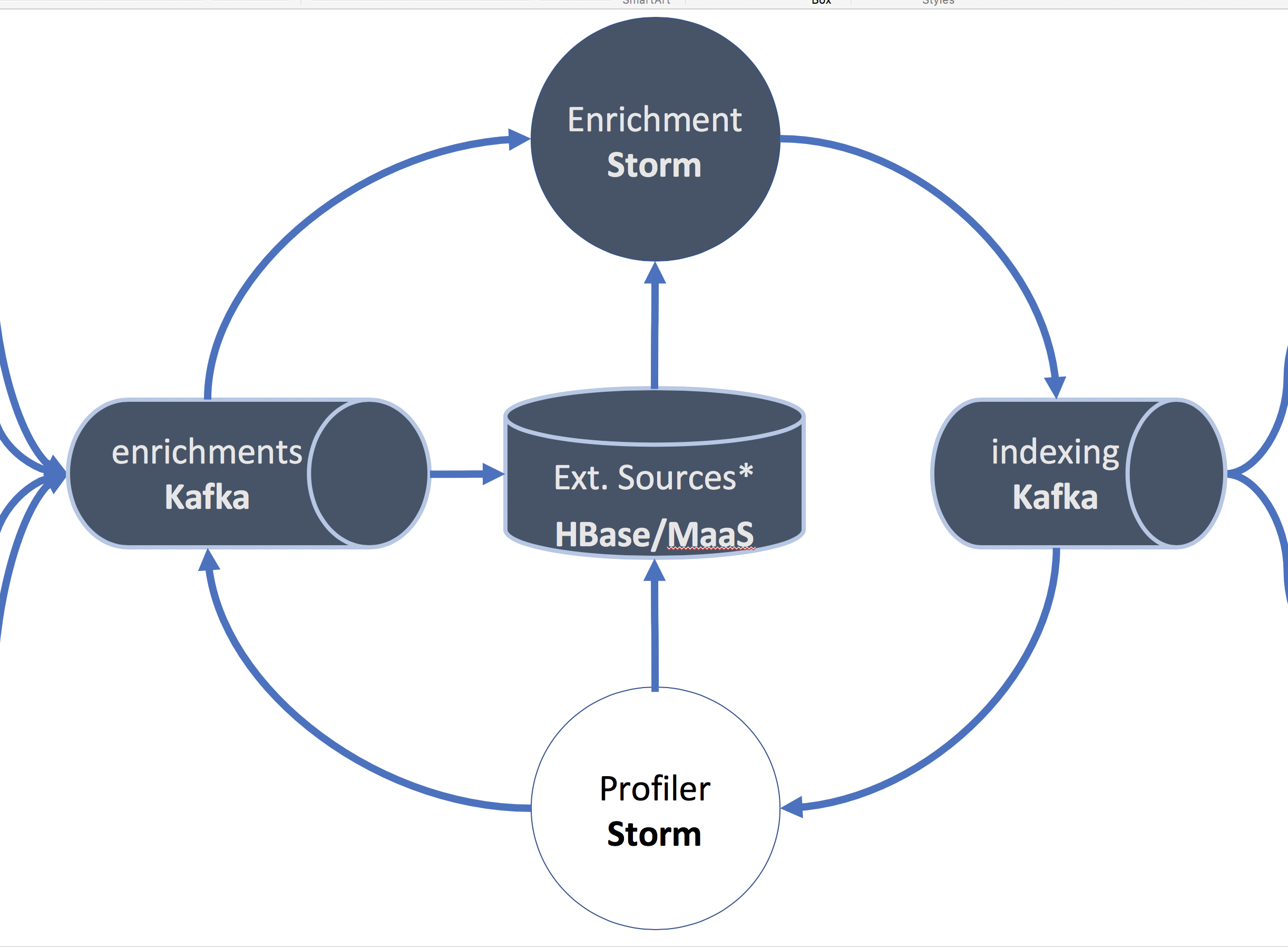
I added a few more details into the figure on the enrichment part:
The enrichment Storm topology is capable of using external database sources on-boarded into HBase or from the Model as a Service (MaaS) capability.
The arrow from the enrichments Kafka topic is not entirely correct, but should depict that data sources coming in in real-time can be stored in HBase as an enrichment source. Correct would be to draw the arrow to HBase directly from the parser topology.
Huge data sets can be fairly easily batch loaded into HBase as an enrichment source.
The profiler is a Storm topology that saves data of certain (user-defined) entities in a time series to HBase. From there it can be used as an enrichment for any future events as aggregates over time.
Open Source Cyber Security with Apache Metron @ Openslava2018
Now I want to shine some light on how the ingestion pipeline architecture looks like. Since I just got started with Apache Metron myself, I hope this helps to kickstart your cyber security efforts. Rather than going too much into the details of what the components do, I’d like to provide a basic overview about which components there are.
This architecture can be generalized for all kinds of streaming use cases. The pipeline uses Apache NiFi for ingest, Apache Kafka as an event buffer, Apache Storm for stream processing, Apache Hadoop for long term storage and Apache Solr for short term random access storage. If you design your own pipeline for a different use case, you can, e.g., swap Apache Storm with frameworks such as Apache Flink or Spark Streaming (or any other frameworks out in the wild with their pros and cons). Choosing the right piece of technology strongly depends on numerous factors, I’m not going into in this article.
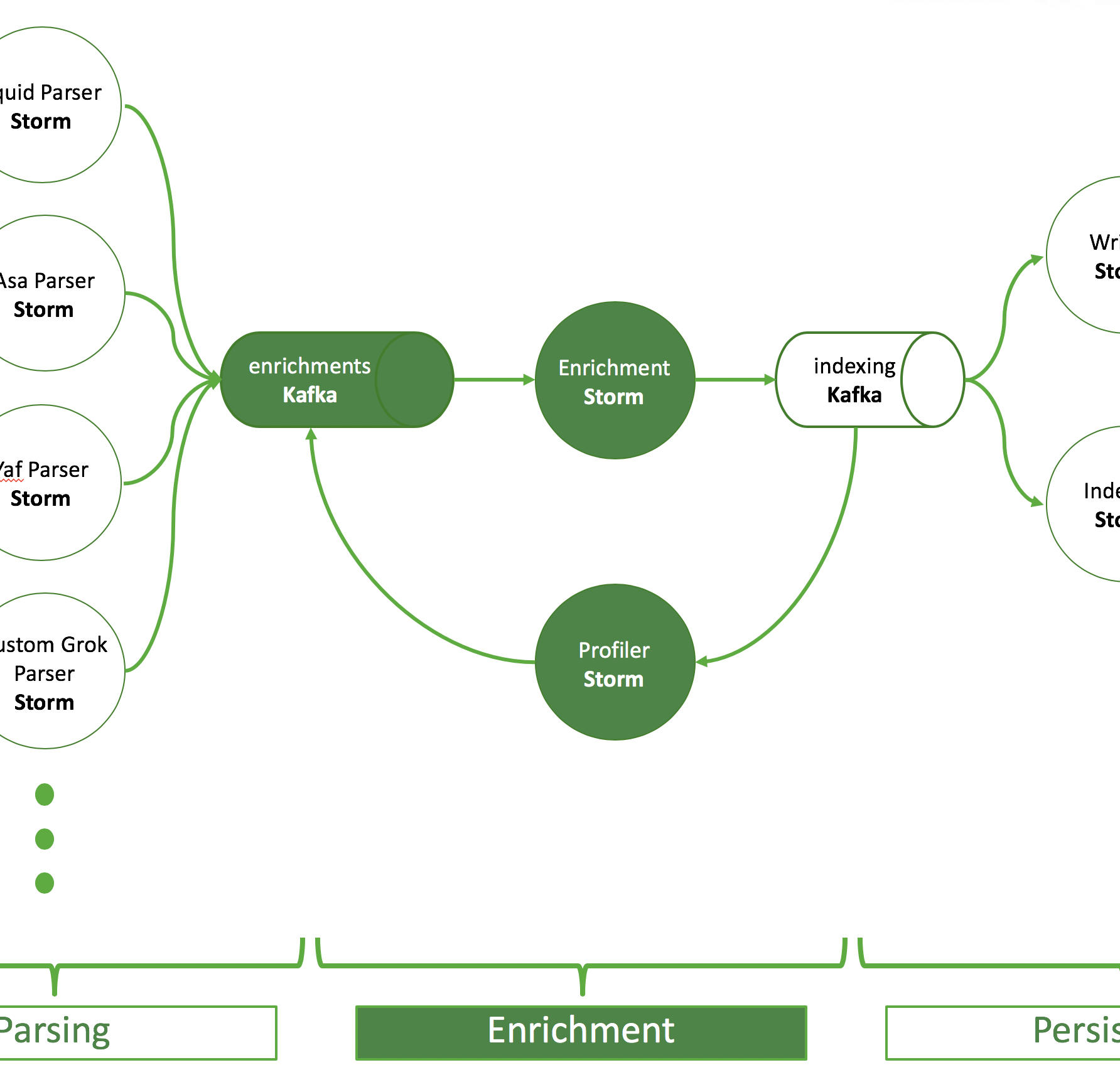
End to End Processing Pipeline for Apache Metron
Ingest
The most important part for Apache Metron is to get the telemetry data into an Apache Kafka topic. In the figure below you can see that there is a Kafka topic and a corresponding parser for each format. Usually, there is one Kafka topic per source type, because each source typically comes in its own special format, but it’s also possible that data of one source has multiple formats or multiple sources have the same format.
Apache NiFi is being used as the data integration tool.
In the figure, I added an example of a MiNiFi instance to the Squid Access Log source. In this case MiNiFi is installed on the Squid server node and acts as a log forwarder.
It’s also possible that sources write directly into Kafka, if they support that. In some cases this might even be a requirement due to performance constraints.
Parsing
As described in the ingest part: there is a topic for each parser format and an Apache Storm topology reading from this Kafka topic and doing the parsing. A parsed event is then written into the so-called “enrichments” topic.
The parsing has two purposes:
it brings all ingest format into a JSON format.
it introduces a common set of fields shared among all data sources, as well as unique fields that are special to each source.
Some parsers of common formats are included in the Metron project.
If there is no parser (that works) for your format, you can use Grok to quickly prototype and launch your parser before you write it in Java.
It is also possible to launch parser chains to extract information that is convoluted in different formats.
You can also decide to run only one topology handling multiple parsers in a so-called aggregated parser. This can be combined with parser chains.
Enrichment
The purpose of the enrichment Storm topology is to pick up events from the enrichments topic and add information from external sources. The enriched output is written to an indexing topic.
A typical enrichment is a lookup in a database to convert an IP address into geo information
The profiler uses sliding windows to create aggregates/statistics in certain time windows, so-called profiles.
These profiles can be used to enrich data.
Metron helps you use any data in HBase to enrich your events.
Persisting
There are two Storm topologies to read from the indexing topic that persist events, the batch indexing topology and the random access indexing topology. The first utilizes an HDFSBolt to write data to HDFS. The latter one indexes data in Apache Solr.
There is one Solr collection per data format.
This way the parsed fields and definitions are kept clean and separated.
Also, you can authorize different users and groups to different data sources. This is even easier with the Solr Plugin for Apache Ranger.
HDFS is used as long term storage for analytical purposes and to use the data to create machine learning models.
Solr is being used for direct fast random access and search capabilities, e.g. by the Metron Alerts UI. It makes sense to store the data for only a limited amount of time for performance reasons.
It’s quite easy to create a new collection. I’ve described it on this github gist. I’ve added properties in the solrconfig.xml to define a “time to live” for an event in Solr, after which the event will be deleted from the collection.
Instead of Solr, you can use Elastic Search.
Conclusion
I hope this can be useful for somebody, either trying to implement Metron or somebody interested in how modern streaming pipelines look like in general. If you have questions, don’t hesitate to ask the experts in the Metron mailing list (user@metron.apache.org) or get support from the Hortonworks Community.
While security is a quite complex topic by itself, security of distributed systems can be overwhelming. Thus, I wrote down a state of the art article about Hadoop (Ecosystem) Security Concepts and also published it on Hortonworks Community Connection.
In the documentation of the particular security related open source projects you can find a number of details on how these components work on their own and which services they rely on. Since the projects are open source you can of course check out the source code for more information. Therefore, this article aims to summarise, rather than explain each process in detail.
In this article I am first going through some basic component descriptions to get an idea which services are in use. Then I explain the “security flow” from a user perspective (authentication –> impersonation (optional) –> authorization –> audit) and provide a short example using Knox.
When reading the article keep following figure in mind. It depicts all the process that I’ll explain.
Provides RESTful API and a UI to manage authorization policies and service access audits based on resources, users, groups and tags.
Ranger User sync:
Syncs users and groups from an LDAP source (OpenLDAP or AD)
Stores users and groups in the relational DB of the Ranger service.
Ranger Plugins:
Service side plugin, that syncs policies from Ranger per default every 30 seconds. That way authorization is possible even if Ranger Admin does not run in HA mode and is currently down.
Ranger Tag Sync:
Syncs tags from Atlas meta data server
Stores tags in the relational DB of the Ranger service.
Ranger Key Management Service (KMS):
Provides a RESTful API to manage encryption keys used for encrypting data at rest in HDFS.
Supporting relational Database:
Contains all policies, synced users, groups, tags
Supporting Apache Solr instances:
Audits are stored here.
Documentation:
For the newest HDP release (2.6.0) use these Ranger Docs
Knox serves as a gateway and proxy for Hadoop services and their UIs so that they can be accessible behind a firewall without requiring to open too many ports in the firewall.
Documentation:
For the newest HDP release (2.6.0) use these Knox Docs
Active Directory
Components:
Authentication Server (AS)
Responsible for issuing Ticket Granting Tickets (TGT)
Ticket Granting Server (TGS)
Responsible for issuing service tickets
Key Distribution Center (KDC)
Talks with clients using KRB5 protocol
AS + TGS
LDAP Server
Contains user and group information and talks with its clients using the LDAP protocol.
Supporting Database
Wire Encryption Concepts
To complete the picture I just want to mention that it is very important, to not only secure the access of services, but also encrypt data transferred between services.
Keystores and Truststores
To enable a secure connection (SSL) between a server and a client, first an encryption key needs to be created. The server uses it to encrypt any communication. The key is securely stored in a keystore for Java services JKS could be used. In order for a client to trust the server, one could export the key from the keystore and import it into a truststore, which is basically a keystore, containing keys of trusted services. In order to enable two-way SSL the same thing needs to be done on the client side. After creating a key in a keystore the client can access, put it into a trust store of the server. Commands to perform these actions are:
Generate key in "/path/to/keystore.jks" setting its alias to "myKeyAlias" and its password to "myKeyPassword". If the keystore file "/path/to/keystore.jks" does not exist, this will command will also create it.
Import key from a file “myKeyFile.cer” with alias “myKeyAlias” into a keystore (that may act as truststore) named “/path/to/truststore.jks” using the password “trustStorePassword”
Only a properly authenticated user (which can also be a service using another service) can communicate successfully with a kerberized Hadoop service. Missing the required authentication, in this case by proving the identity of both user and the service, any communication will fail. In a kerberized environment user authentication is provided via a ticket granting ticket (TGT).
Note: Not using KERBEROS, but SIMPLE authentication, which is set up by default, provides any user with the possibility to act as any other type of user, including the superuser. Therefore strong authentication using Kerberos is highly encouraged.
Technical Authentication Flow:
User requests TGT from AS. This is done automatically upon login or using the kinit command.
User receives TGT from AS.
User sends request to a kerberized service.
User gets service ticket from Ticket Granting Server. This is done automatically in the background when user sends a request to the service.
User sends service a request to the service using the service ticket.
Authentication Flow from a User Perspective:
Most of the above processes are hidden from the user. The only thing, the user needs to do before issuing a request from the service is to login on a machine and thereby receive a TGT or receive it programmatically or obtain it manually using the kinit command.
Impersonation
This is the second step after a user is successfully authenticated at a service. The user must be authenticated, but can then choose to perform the request to the service as another user. If everyone could do this by default, this would raise another security concern and the authentication process would be futile. Therefore this behaviour is forbidden by default for everyone and must be granted for individual users. It is used by proxy services like Apache Ambari, Apache Zeppelin or Apache Knox. Ambari, Zeppelin and Knox authenticate as “ambari”, “zeppelin”, “knox” users, respectively, at the service using their TGTs, but can choose to act on behalf of the person, who is logged in in the browser in Ambari, Zeppelin or Knox. This is why it is very important to secure these services.
To allow, for example, Ambari to perform operations as another user, set the following configs in the core-site.xml, hadoop.proxyuser.ambari.groups and hadoop.proxyuser.ambari.hosts, to a list of groups or hosts that are allowed to be impersonated or set a wildcard *.
Authorization
Authorization defines the permissions of individual users. After it is clear which user will be performing the request, i.e., the actually authenticated or the impersonated one, the service checks against the local Apache Ranger policies, if the request is allowed for this certain user. This is the last instance in the process. A user passing this step is eventually allowed to perform the requested action.
Audit
Every time the authorization instance is called, i.e., policies are checked if the action of a user is authorized or not, an audit event is being logged, containing, time, user, service, action, data set and success of the event. An event is not logged in Ranger in case a user without authentication tries to access data or if a user tries to impersonate another user, without having appropriate permissions to do so.
Example Security Flow Using Apache Knox
Looking at the figure above you can follow what’s going on in the background, when a user Eric wants to push a file into the HDFS service on path “/user/eric/” from outside the Hadoop cluster firewall.
User Eric sends the HDFS request including the file and the command to put that file into the desired directory, while authenticating successfully via LDAP provider at the Apache Knox gateway using his username/password combination. Eric does not need to obtain a Kerberos ticket. In fact, since he is outside the cluster, he probably does not have access to the KDC through the firewall to obtain one anyway.
Knox Ranger plugin checks, if Eric is allowed to use Knox. If he’s not, the process ends here. This event is logged in Ranger audits.
Knox has a valid TGT (and refreshes it before it becomes invalid), obtains a service ticket with it and authenticates at the HDFS namenode as user “knox”.
Knox asks the service to perform the action as Eric, which is configured to be allowed.
Ranger HDFS plugin checks, if Eric has the permission to “WRITE” to “/user/eric”. If he’s not, the process ends here. This event is logged in Ranger audits.
File is pushed to HDFS.
I hope this article helps to get a better understanding of the security concepts within the Hadoop Ecosystem.