
In my previous blog post I was writing a little bit about what Apache Metron is and How to Onboard a New Data Source in Apache Metron.
Now I want to shine some light on how the ingestion pipeline architecture looks like. Since I just got started with Apache Metron myself, I hope this helps to kickstart your cyber security efforts. Rather than going too much into the details of what the components do, I’d like to provide a basic overview about which components there are.
This architecture can be generalized for all kinds of streaming use cases. The pipeline uses Apache NiFi for ingest, Apache Kafka as an event buffer, Apache Storm for stream processing, Apache Hadoop for long term storage and Apache Solr for short term random access storage. If you design your own pipeline for a different use case, you can, e.g., swap Apache Storm with frameworks such as Apache Flink or Spark Streaming (or any other frameworks out in the wild with their pros and cons). Choosing the right piece of technology strongly depends on numerous factors, I’m not going into in this article.

Ingest
The most important part for Apache Metron is to get the telemetry data into an Apache Kafka topic. In the figure below you can see that there is a Kafka topic and a corresponding parser for each format. Usually, there is one Kafka topic per source type, because each source typically comes in its own special format, but it’s also possible that data of one source has multiple formats or multiple sources have the same format.

- Apache NiFi is being used as the data integration tool.
- In the figure, I added an example of a MiNiFi instance to the Squid Access Log source. In this case MiNiFi is installed on the Squid server node and acts as a log forwarder.
- It’s also possible that sources write directly into Kafka, if they support that. In some cases this might even be a requirement due to performance constraints.
Parsing
As described in the ingest part: there is a topic for each parser format and an Apache Storm topology reading from this Kafka topic and doing the parsing. A parsed event is then written into the so-called “enrichments” topic.

- The parsing has two purposes:
- it brings all ingest format into a JSON format.
- it introduces a common set of fields shared among all data sources, as well as unique fields that are special to each source.
- Some parsers of common formats are included in the Metron project.
- If there is no parser (that works) for your format, you can use Grok to quickly prototype and launch your parser before you write it in Java.
- It is also possible to launch parser chains to extract information that is convoluted in different formats.
- You can also decide to run only one topology handling multiple parsers in a so-called aggregated parser. This can be combined with parser chains.
Enrichment
The purpose of the enrichment Storm topology is to pick up events from the enrichments topic and add information from external sources. The enriched output is written to an indexing topic.
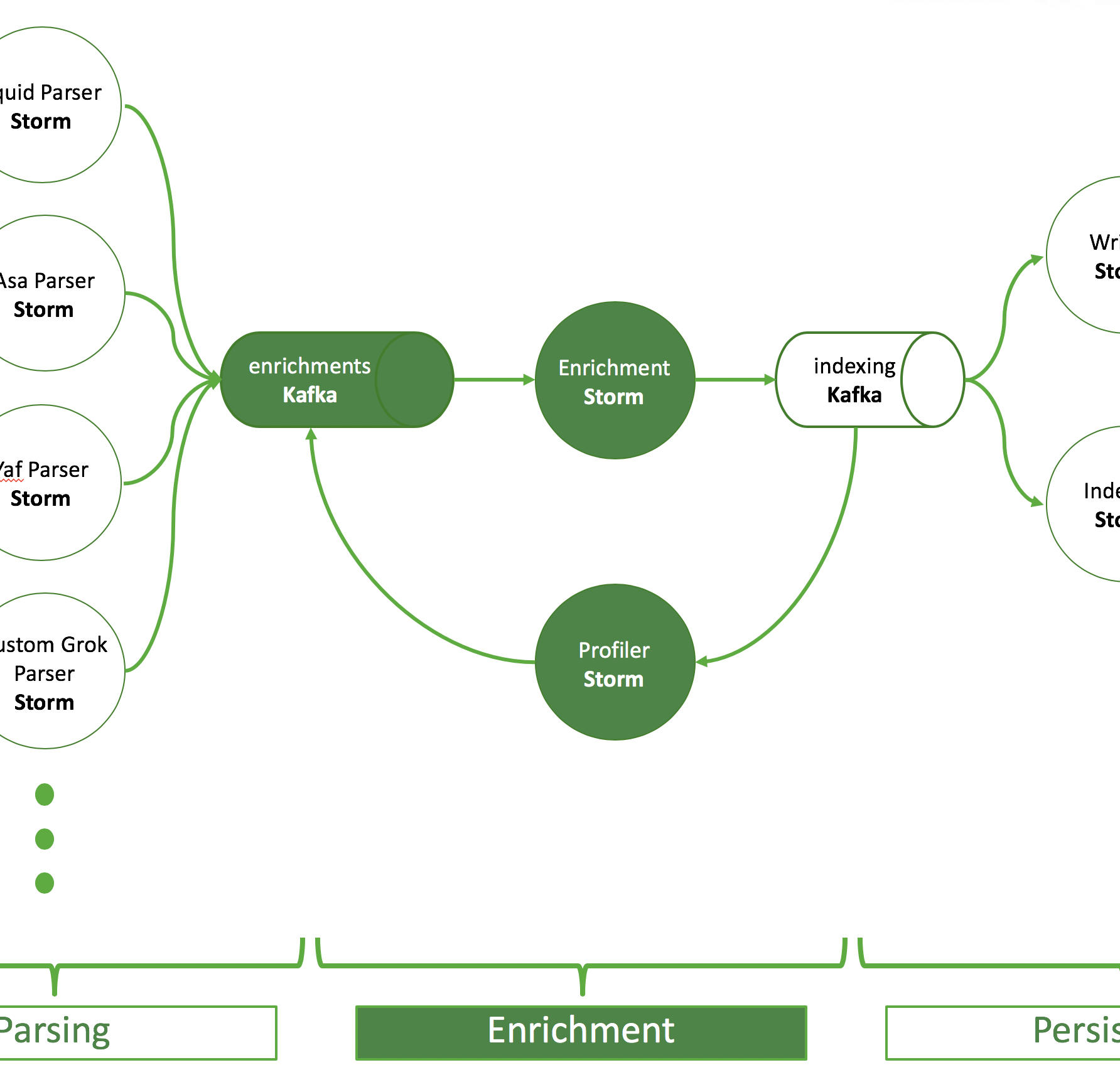
- A typical enrichment is a lookup in a database to convert an IP address into geo information
- The profiler uses sliding windows to create aggregates/statistics in certain time windows, so-called profiles.
- These profiles can be used to enrich data.
- Metron helps you use any data in HBase to enrich your events.
Persisting
There are two Storm topologies to read from the indexing topic that persist events, the batch indexing topology and the random access indexing topology. The first utilizes an HDFSBolt to write data to HDFS. The latter one indexes data in Apache Solr.

- There is one Solr collection per data format.
- This way the parsed fields and definitions are kept clean and separated.
- Also, you can authorize different users and groups to different data sources. This is even easier with the Solr Plugin for Apache Ranger.
- HDFS is used as long term storage for analytical purposes and to use the data to create machine learning models.
- Solr is being used for direct fast random access and search capabilities, e.g. by the Metron Alerts UI. It makes sense to store the data for only a limited amount of time for performance reasons.
- It’s quite easy to create a new collection. I’ve described it on this github gist. I’ve added properties in the solrconfig.xml to define a “time to live” for an event in Solr, after which the event will be deleted from the collection.
- Instead of Solr, you can use Elastic Search.
Conclusion
I hope this can be useful for somebody, either trying to implement Metron or somebody interested in how modern streaming pipelines look like in general. If you have questions, don’t hesitate to ask the experts in the Metron mailing list (user@metron.apache.org) or get support from the Hortonworks Community.

